1
¿QUÉ ES LA ESTADÍSTICA?
La estadística es el lenguaje universal de las ciencias. El empleo cuidadoso de los métodos estadísticos permite
obtener información precisa de los datos. Estos métodos incluyen:
• definir cuidadosamente la situación,
• obtener los datos,
• resumir con precisión los datos y
• obtener y comunicar las conclusiones importantes.
La estadística implica información, números y gráficas visuales para resumir esta información, y su
interpretación.
El termino estadística se refiere a datos numéricos, tales como promedios, medianas, porcentajes y números
índices que ayudan a entender una gran variedad de negocios y situaciones económicas. Sin embargo, como
se verá, el campo de la estadística es mucho más que datos numéricos. En un sentido amplio, la estadística se
define como el arte y la ciencia de reunir datos, analizarlos, presentarlos e interpretarlos. Especialmente en
los negocios y en la economía, la información obtenida al reunir datos, analizarlos, presentarlos e
interpretarlos proporciona a directivos, administradores y personas que deben tomar decisiones una mejor
comprensión del negocio o entorno económico, permitiéndoles así tomar mejores decisiones con base en
mejor información.
El terreno de la estadística puede dividirse a grandes rasgos en dos campos de acción: estadística descriptiva
y estadística inferencial. La estadística descriptiva incluye la obtención, presentación y descripción de los
datos muestrales. El término estadística inferencial se refiere a la técnica de interpretación de los valores
resultantes de las técnicas descriptivas y la toma de decisiones, así como a la obtención de conclusiones
relativas a la población.
Estadística descriptiva:
La mayor parte de la información estadística en periódicos, revistas, informes de empresas y otras
publicaciones consta de datos que se resumen y presentan en una forma fácil de leer y de entender. A estos
resúmenes de datos, que pueden ser tabulares, gráficos o numéricos se les conoce como estadística
descriptiva.
Los métodos de la estadística descriptiva pueden emplearse para resumir la información en este conjunto de
datos. Estos tipos de resúmenes, tabular y gráfico, permiten que los datos sean más fáciles de interpretar.
Además de las presentaciones tabular y gráfica para resumir datos se emplea también la estadística descriptiva
numérica. El estadístico descriptivo más común para resumir datos es el promedio o media.
Inferencia estadística:
En muchas situaciones se requiere información acerca de grupos grandes de elementos (individuos, empresas,
votantes, hogares, productos, clientes, etc.). Pero, debido al tiempo, costo y a otras consideraciones, sólo es
posible recolectar los datos de una pequeña parte de este grupo. Al grupo grande de elementos en un
determinado estudio se le llama población y al grupo pequeño muestra.
Una de las principales contribuciones de la estadística es emplear datos de una muestra para hacer
estimaciones y probar hipótesis acerca de las características de una población mediante un proceso al que se
le conoce como inferencia estadística.
MocaWeb.ar

2
La estadística es más que sólo números: son los datos, lo que se hace con ellos, lo que se aprende de los datos
y las conclusiones resultantes.
Estadística: es la ciencia que se encarga de obtener, describir e interpretar los datos.
DATOS
Datos son hechos/informaciones y cifras que se recogen, analizan y resumen para su presentación e
interpretación. A todos los datos reunidos para un determinado estudio se les llama conjunto de datos para
el estudio.
Dato: es el valor de la variable asociada a un elemento de una población o muestra. Este valor puede ser un
número, una palabra o un símbolo.
Datos: son el conjunto de valores que se obtienen de la variable a partir de cada uno de los elementos que
pertenecen a la muestra.
Escalas de medición
La recolección de datos requiere alguna de las escalas de medición siguientes: nominal, ordinal, de intervalo
o de razón. La escala de medición determina la cantidad de información contenida en el dato e indica la
manera más apropiada de resumir y de analizar estadísticamente los datos.
Cuando el dato de una variable es una etiqueta o un nombre que identifica un atributo de un elemento, se
considera que la escala de medición es una escala nominal. Cuando la escala de medición es nominal, se usa
un código o una etiqueta no numérica.
Una escala de medición para una variable es ordinal si los datos muestran las propiedades de los datos
nominales y además tiene sentido el orden o jerarquía de los datos.
Una escala de medición para una variable es una escala de intervalo si los datos tienen las características de
los datos ordinales y el intervalo entre valores se expresa en términos de una unidad de medición fija. Los
datos de intervalo siempre son numéricos.
Una variable tiene una escala de razón si los datos tienen todas las propiedades de los datos de intervalo y la
proporción entre dos valores tiene significado. Variables como distancia, altura, peso y tiempo usan la escala
de razón en la medición. Esta escala requiere que se tenga el valor cero para indicar que en este punto no
existe la variable.
Elementos, variables y observaciones
Elementos son las entidades de las que se obtienen los datos.
Una variable es una característica de los elementos que es de interés.
Los valores encontrados para cada variable en cada uno de los elementos constituyen los datos. Al conjunto
de mediciones obtenidas para un determinado elemento se le llama observación.
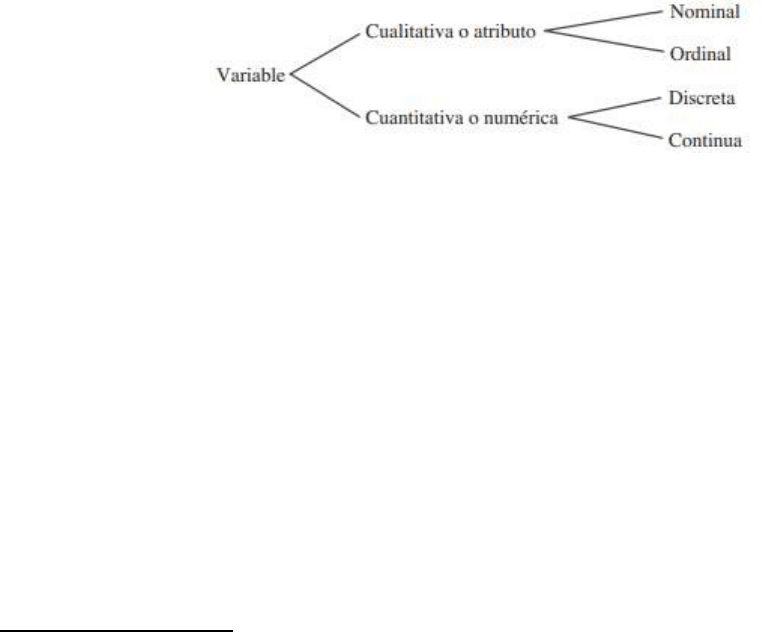
Básicamente, hay dos clases de variables: 1) variables que resultan en información cualitativa y (2) variables
que resultan en información cuantitativa.
Variable cualitativa, de atributos, o categórica: es una variable que clasifica o describe a un elemento de una
población.
Variable cuantitativa o numérica: es aquella que cuantifica un elemento de una población.
3
Algunas operaciones aritméticas, como sumar y promediar, tienen sentido para los datos que resultan de una
variable cuantitativa. Cada uno de estos tipos de variables (cualitativas y cuantitativas) pueden subdividirse
aún más, como se ilustra en el diagrama siguiente.
Variable nominal: es una variable cualitativa que caracteriza (describe o identifica) a un elemento de una
población. Para los datos resultantes de una variable nominal, las operaciones aritméticas no sólo carecen de
sentido, sino que tampoco se puede asignar un orden a las categorías.
Variable ordinal: es una variable cualitativa que presenta una posición, o clasificación, ordenada.
Variable discreta: es una variable cuantitativa que puede asumir un número contable (o finito) de valores.
Intuitivamente, la variable discreta puede asumir los valores correspondientes a puntos aislados a lo largo de
un intervalo de recta. Es decir, entre dos valores cualesquiera siempre hay un hueco.
Variable continua: es una variable cuantitativa que puede asumir una cantidad incontable de valores.
Intuitivamente, la variable continua puede asumir cualquier valor a lo largo de un intervalo de recta,
incluyendo cualquier valor posible entre dos variables determinadas.
En muchos casos, es posible distinguir los dos tipos de variables decidiendo si las variables están relacionadas
con un conteo o una medición.
Población y Muestra
El concepto de una población es la idea más importante en estadística.
Población: es la colección, o conjunto, de individuos, objetos o eventos cuyas propiedades serán analizadas
La población es la colección completa de individuos u objetos de interés para la persona que obtiene los datos
de la muestra. La población de interés debe definirse cuidadosamente y se considera que está definida por
completo sólo cuando se especifica la lista de elementos que pertenecen a ella.
Hay dos tipos de poblaciones: finitas e infinitas. Cuando se puede enumerar físicamente a todos los elementos
que componen a una población se dice que la población es finita. Cuando los elementos son ilimitados, se dice
que la población es infinita
El estudio de grandes poblaciones se dificulta grandemente, en consecuencia, se acostumbra seleccionar una
muestra y estudiar los datos que la integran.
Muestra: es el subconjunto de una población. Una muestra está integrada por los individuos, objetos o
medidas seleccionados de la población por la persona que obtiene los elementos de la muestra.
Experimento: es una actividad planeada cuyos resultados producen un conjunto de datos.
Un experimento incluye las actividades tanto para seleccionar los elementos como para obtener los valores
de los datos.
Parámetro: es un valor numérico que resume todos los datos de una población completa.

4
Para todo parámetro existe un estadístico muestral correspondiente. La estadística describe a la muestra en
la misma forma que el parámetro describe a la población.
Estadístico: es un valor numérico que resume los datos de la muestra…
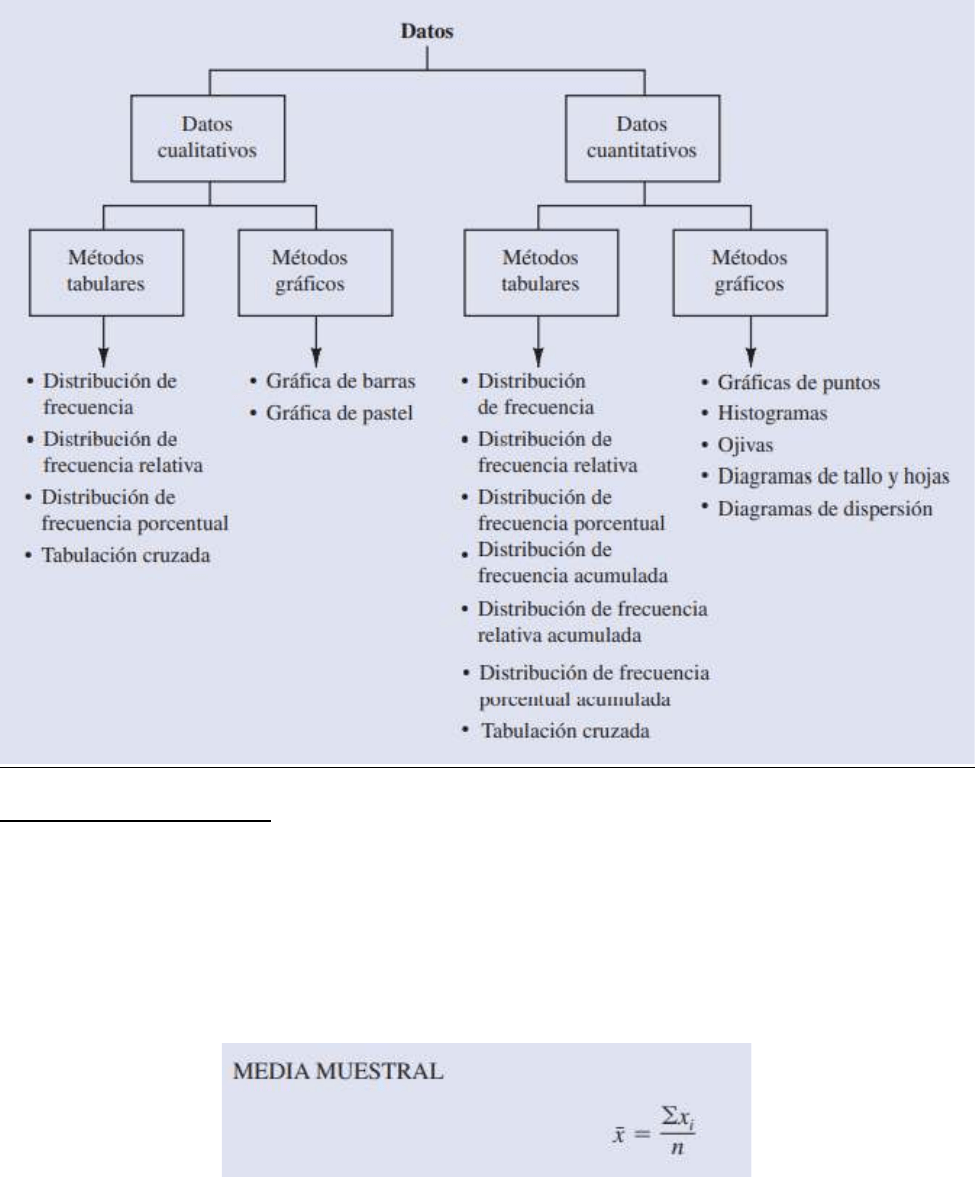
Resumen de datos cualitativos
Distribuciones de frecuencias
Distribución de frecuencia: es una lista que se expresa con cierta frecuencia en forma de gráfica, que enlaza
pares de valores de una variable con su frecuencia. Una distribución de frecuencia es un resumen tabular de
datos que muestra el número (frecuencia) de elementos en cada una de las diferentes clases disyuntas (que
no se sobreponen).
La distribución de frecuencia resume la información. El resumen aporta más claridad que los datos originales.
Distribuciones de frecuencia relativa y de frecuencia porcentual
En una distribución de frecuencia se aprecia el número (frecuencia) de los elementos de cada una de las
diversas clases disyuntas. Sin embargo, con frecuencia lo que interesa es la proporción o porcentaje de
elementos en cada clase. La frecuencia relativa de una clase es igual a la parte o proporción de los elementos
que pertenecen a cada clase. En un conjunto de datos, en el que hay n observaciones, la frecuencia relativa
de cada clase se determina como sigue:
La frecuencia porcentual de una clase es la frecuencia relativa multiplicada por 100.
Una distribución de frecuencia relativa da un resumen tabular de datos en el que se muestra la frecuencia
relativa de cada clase. Una distribución de frecuencia porcentual da la frecuencia porcentual de los datos de
cada clase.
Gráficas de barra y gráficas de pastel
Una gráfica de barras o un diagrama de barras, es una gráfica para representar los datos cualitativos de una
distribución de frecuencia, de frecuencia relativa o de frecuencia porcentual. En uno de los ejes de la gráfica
(por lo general en el horizontal), se especifican las etiquetas empleadas para las clases (categorías). Para el
otro eje de la gráfica (el vertical) se usa una escala para frecuencia, frecuencia relativa o frecuencia porcentual.
Después, empleando un ancho de barra fijo, se dibuja sobre cada etiqueta de las clases una barra que se
extiende hasta la frecuencia, frecuencia relativa o frecuencia porcentual de la clase.
La gráfica de pastel proporciona otra gráfica para presentar distribuciones de frecuencia relativa y de
frecuencia porcentual de datos cualitativos. Para elaborar una gráfica de pastel, primero se dibuja un círculo
que representa todos los datos. Después se usa la frecuencia relativa para subdividir el círculo en sectores, o
partes, que corresponden a la frecuencia relativa de cada clase.
Resumen de datos cuantitativos

5
Distribución de frecuencia
Una distribución de frecuencia es un resumen de datos tabular que presenta el número de elementos
(frecuencia) en cada una de las clases disyuntas. Esta definición es válida tanto para datos cualitativos como
cuantitativos. Sin embargo, cuando se trata de datos cuantitativos se debe tener más cuidado al definir las
clases disyuntas que se van a usar en la distribución de frecuencia.
Los tres pasos necesarios para definir las clases de una distribución de frecuencia con datos cuantitativos son:
1. Determinar el número de clases disyuntas.
2. Determinar el ancho de cada clase
3. Determinar los límites de clase.
Número de clases: Las clases se forman especificando los intervalos que se usarán para agrupar los datos. Se
recomienda emplear entre 5 y 20 clases. La idea es tener las clases suficientes para que se muestre la variación
en los datos, pero no deben ser demasiadas si algunas de ellas contienen sólo unos cuantos datos.
Ancho de clase: El segundo paso al construir una distribución de frecuencia para datos cuantitativos es elegir
el ancho de las clases. Como regla general es recomendable que el ancho sea el mismo para todas las clases.
Así, el ancho y el número de clases no son decisiones independientes. Entre mayor sea el número de clases
menor es el ancho de las clases y viceversa. Para determinar el ancho de clase apropiada se empieza por
identificar el mayor y el menor de los valores de los datos. Después, usando el número de clases deseado, se
emplea la expresión siguiente para determinar el ancho aproximada de clase.
El ancho aproximado de clase que se obtiene con la ecuación se redondea a un valor más adecuado de acuerdo
con las preferencias de la persona que elabora la distribución de frecuencia.
En la práctica el número de clases y su ancho adecuado se determinan por prueba y error. El analista determina
la combinación de número y ancho de clases que le proporciona la mejor distribución de frecuencia para
resumir los datos.
Límites de clase: Los límites de clase deben elegirse de manera que cada dato pertenezca a una y sólo una de
las clases. El límite de clase inferior indica el menor valor de los datos a que pertenece esa clase. El límite de
clase superior indica el mayor valor de los datos a que pertenece esa clase. Al elaborar distribuciones de
frecuencia para datos cualitativos, no es necesario especificar límites de clase porque cada dato corresponde
de manera natural a una de las clases disyuntas. Pero con datos cuantitativos, los límites de clase son
necesarios para determinar dónde colocar cada dato.
Una vez determinados números, ancho y límites de las clases, la distribución de frecuencia se obtiene
contando el número de datos que corresponden a cada clase.
Punto medio de clase: En algunas aplicaciones se desea conocer el punto medio de las clases de una
distribución de frecuencia de datos cuantitativos. El punto medio de clase es el valor que queda a la mitad
entre el límite inferior y el límite superior.
Las distribuciones de frecuencia relativa y de frecuencia porcentual para datos cuantitativos se definen de la
misma forma que para datos cualitativos. Primero debe recordar que la frecuencia relativa es el cociente,
respecto al total de observaciones, de las observaciones que pertenecen a una clase. Si el número de
observaciones es n,

6
La frecuencia porcentual de una clase es la frecuencia relativa multiplicada por 100.
Gráficas de puntos
Uno de los más sencillos resúmenes gráficos de datos son las gráficas de puntos. En el eje horizontal se
presenta el intervalo de los datos. Cada dato se representa por un punto colocado sobre este eje. Son útiles
para comparar la distribución de los datos de dos o más variables.
Histograma
Una presentación gráfica usual para datos cuantitativos es el histograma. Esta gráfica se hace con datos
previamente resumidos mediante una distribución de frecuencia, de frecuencia relativa o de frecuencia
porcentual. Un histograma se construye colocando la variable de interés en el eje horizontal y la frecuencia,
la frecuencia relativa o la frecuencia porcentual en el eje vertical. La frecuencia, frecuencia relativa o
frecuencia porcentual de cada clase se indica dibujando un rectángulo cuya base está determinada por los
límites de clase sobre el eje horizontal y cuya altura es la frecuencia, la frecuencia relativa o la frecuencia
porcentual correspondiente.
Cuando se construye un histograma se eliminan estos espacios. Eliminar los espacios entre las clases del
histograma de las duraciones de las auditorías sirve para indicar que todos los valores entre el límite inferior
de la primera clase y el superior de la última son posibles.
Uno de los usos más importantes de un histograma es proveer información acerca de la forma de la
distribución. Se dice que un histograma es sesgado a la izquierda si su cola se extiende más hacia la izquierda.
Un histograma está sesgado a la derecha si su cola se extiende más hacia la derecha. Un histograma simétrico.
En éste la cola izquierda es la imagen de la cola derecha. Los histogramas de datos para aplicaciones nunca
son perfectamente simétricos, pero en muchas aplicaciones suelen ser más o menos simétricos. Los datos de
aplicaciones de negocios o economía suelen conducir a histogramas sesgados a la derecha.
Distribuciones acumuladas
Una variación de las distribuciones de frecuencia que proporcionan otro resumen tabular de datos
cuantitativos es la distribución de frecuencia acumulada. La distribución de frecuencia acumulada usa la
cantidad, las amplitudes y los límites de las clases de la distribución de frecuencia. Sin embargo, en lugar de
mostrar la frecuencia de cada clase, la distribución de frecuencia acumulada muestra la cantidad de datos que
tienen un valor menor o igual al límite superior de cada clase.
La frecuencia acumulada es simplemente la suma de la frecuencia de todas las clases en que los valores de los
datos son menores o iguales.
Por último, se tiene que la distribución de frecuencias relativas acumuladas indica la proporción de todos los
datos que tienen valores menores o iguales al límite superior de cada clase, y la distribución de frecuencias
porcentuales acumuladas indica el porcentaje de todos los datos que tienen valores menores o iguales al límite
superior de cada clase. La distribución de frecuencias relativas acumuladas se calcula ya sea sumando las
frecuencias relativas que aparecen en la distribución de frecuencias relativas o dividiendo la frecuencia
acumulada entre la cantidad total de datos. Las frecuencias porcentuales acumuladas se obtienen
multiplicando las frecuencias relativas por 100.
7
Ojiva
La gráfica de una distribución acumulada, llamada ojiva, es una gráfica que muestra los valores de los datos
en el eje horizontal y las frecuencias acumuladas, las frecuencias relativas acumuladas o las frecuencias
porcentuales acumuladas en el eje vertical.
La ojiva se construye al graficar cada uno de los puntos correspondientes a la frecuencia acumulada de las
clases.
Diagrama de dispersión y línea de tendencia
Un diagrama de dispersión es una representación gráfica de la relación entre dos variables cuantitativas y una
línea de tendencia es una línea que da una aproximación de la relación. En el diagrama de dispersión se grafica
un punto con las coordenadas.
MÉTODOS TABULARES Y GRÁFICOS PARA RESUMIR DATOS
8
Medidas de localización
MEDIA
La medida de localización más importante es la media, o valor promedio, de una variable. La media
proporciona una medida de localización central de los datos. Si los datos son datos de una muestra, la media
se denota; si los datos son datos de una población, la media se denota con la letra griega μ.
La fórmula para la media muestral cuando se tiene una muestra de n observaciones es la siguiente.
En la fórmula anterior el numerador es la suma de los valores de las n observaciones.
Para calcular la media de una población use la misma fórmula, pero con una notación diferente para indicar
que trabaja con toda la población. El número de observaciones en una población se denota N y el símbolo
para la media poblacional es μ.

9
MEDIANA
La mediana es otra medida de localización central. Es el valor de en medio en los datos ordenados de menor
a mayor (en forma ascendente). Cuando tiene un número impar de observaciones, la mediana es el valor de
en medio. Cuando la cantidad de observaciones es par, no hay un número en medio. En este caso, se sigue
una convención y la mediana es definida como el promedio de las dos observaciones de en medio.
MODA
La tercera medida de localización es la moda. La moda se define como el valor que se presenta con mayor
frecuencia.
Hay situaciones en que la frecuencia mayor se presenta con dos o más valores distintos. Cuando esto ocurre
hay más de una moda. Si los datos contienen más de una moda se dice que los datos son bimodales. Si
contienen más de dos modas, son multimodales. En los casos multimodales casi nunca se da la moda, porque
dar tres o más modas no resulta de mucha ayuda para describir la localización de los datos.
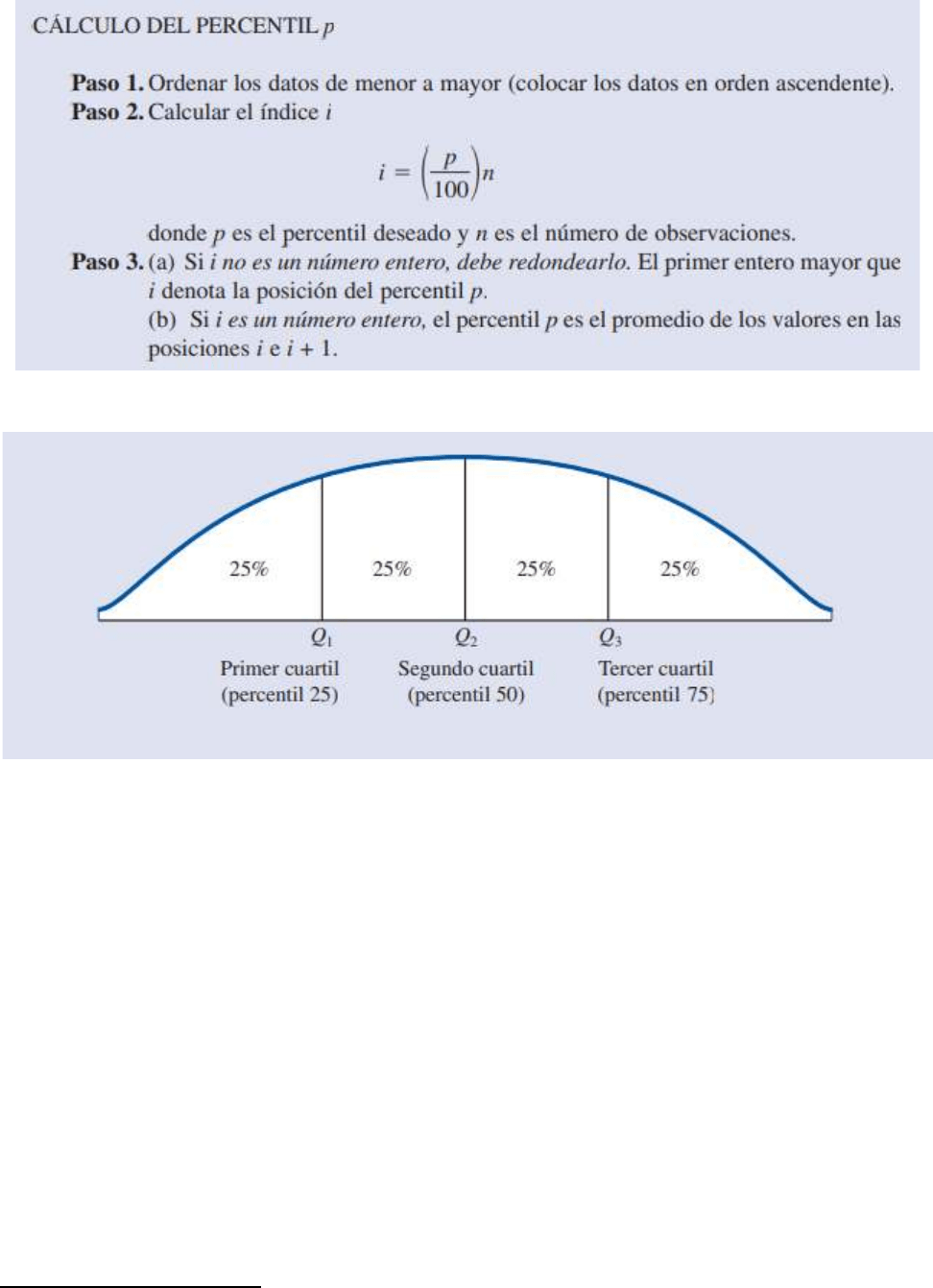
PERCENTILES
Un percentil aporta información acerca de la dispersión de los datos en el intervalo que va del menor al mayor
valor de los datos. En los conjuntos de datos que no tienen muchos valores repetidos, el percentil p divide a
los datos en dos partes.
Para calcular el percentil p se emplea el procedimiento siguiente:
10
LOCALIZACIÓN DE LOS CUARTILES
El percentil 50 coincide con la mediana.
CUARTILES
Con frecuencia es conveniente dividir los datos en cuatro partes; así, cada parte contiene una cuarta parte o
25% de las observaciones.
A los puntos de división se les conoce como cuartiles y están definidos como sigue:
Q1 = primer cuartil, o percentil 25
Q2 = segundo cuartil, o percentil 50
Q3 = tercer cuartil, o percentil 75
Los cuartiles dividen los datos de los sueldos iniciales en cuatro partes y cada parte contiene 25% de las
observaciones.
Los cuartiles han sido definidos como el percentil 25, el percentil 50 y el percentil 75. Por lo que los cuartiles
se calculan de la misma manera que los percentiles.
Medidas de variabilidad

11
Además de las medidas de localización, suele ser útil considerar las medidas de variabilidad o de dispersión.
RANGO
La medida de variabilidad más sencilla es el rango.
Aunque el rango es la medida de variabilidad más fácil de calcular, rara vez se usa como única medida. La razón
es que el rango se basa sólo en dos observaciones y, por tanto, los valores extremos tienen una gran influencia
sobre él.
RANGO INTERCUARTÍLICO
Una medida que no es afectada por los valores extremos es el rango intercuartílico (RIC). Esta medida de
variabilidad es la diferencia entre el tercer cuartil Q3 y el primer cuartil Q1. En otras palabras, el rango
intercuartílico es el rango en que se encuentra el 50% central de los datos.
VARIANZA
La varianza es una medida de variabilidad que utiliza todos los datos. La varianza está basada en la diferencia
entre el valor de cada observación (xi) y la media. A la diferencia entre cada valor xi y la media se le llama
desviación respecto de la media.
Para calcular la varianza, estas desviaciones respecto de la media se elevan al cuadrado.
Al comparar variables, la que tiene la varianza mayor, muestra más variabilidad.
En todo conjunto de datos, la suma de las desviaciones respecto de la media será siempre igual a cero.
DESVIACIÓN ESTÁNDAR
La desviación estándar se define como la raíz cuadrada positiva de la varianza. Se emplea s para denotar la
desviación estándar muestral y σ para denotar la desviación estándar poblacional.

12
La desviación estándar se mide en las mismas unidades que los datos originales. Por esta razón es más fácil
comparar la desviación estándar con la media y con otros estadísticos que se miden en las mismas unidades
que los datos originales.
COEFICIENTE DE VARIACIÓN
En algunas ocasiones se requiere un estadístico descriptivo que indique cuán grande es la desviación estándar
en relación con la media. Esta medida es el coeficiente de variación y se representa como porcentaje.
En general, el coeficiente de variación es un estadístico útil para comparar la variabilidad de variables que
tienen desviaciones estándar distintas y medias distintas.
DETECCIÓN DE OBSERVACIONES ATÍPICAS
Algunas veces un conjunto de datos tiene una o más observaciones cuyos valores son mucho más grandes o
mucho más pequeños que la mayoría de los datos. A estos valores extremos se les llama observaciones
atípicas. Las personas que se dedican a la estadística y con experiencia en ella toman medidas para identificar
estas observaciones atípicas y después las revisan con cuidado. Una observación extraña quizá sea el valor de
un dato que se anotó de modo incorrecto. Si es así puede corregirse antes de continuar con el análisis. Una
observación atípica tal vez provenga, también, de una observación que se incluyó indebidamente en el
conjunto de datos; si es así se puede eliminar. Por último, una observación atípica quizá es un dato con un
valor inusual, anotado correctamente y que sí pertenece al conjunto de datos. En tal caso debe conservarse.
Resumen de cinco números
En el resumen de cinco números se usan los cinco números siguientes para resumir los datos.
1. El valor menor.
2. El primer cuartil (Q1).
3. La mediana (Q2)
4. El tercer cuartil (Q3).
5. El valor mayor.
DIAGRAMA DE CAJA
Un diagrama de caja es un resumen gráfico de los datos con base en el resumen de cinco números. La clave
para la elaboración de un diagrama de caja es el cálculo de la mediana y de los cuartiles Q1 y Q3 También se
necesita el rango intercuartílico, RIC = Q3 - Q1.
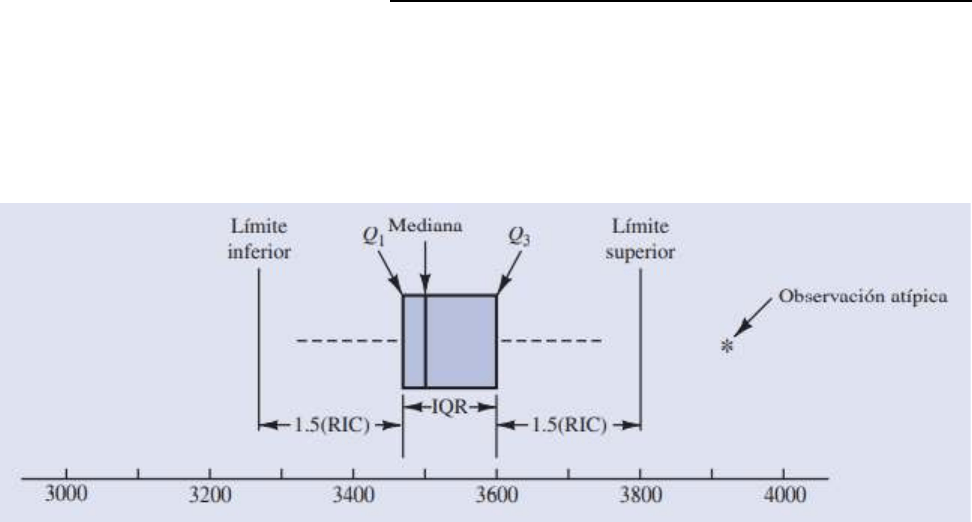
13
1. Se dibuja una caja cuyos extremos se localicen en el primer y tercer cuartiles. Esta caja contiene 50%
de los datos centrales.
2. En el punto donde se localiza la mediana se traza una línea vertical.
3. Usando el rango intercuartílico, RIC
Q3 – Q1, se localizan los límites. En un diagrama de caja los límites se encuentran 1.5(RIC) abajo del
Q1 y 1.5(RIC) arriba del Q3. Los datos que quedan fuera de estos límites se consideran observaciones
atípicas.
4. A las líneas punteadas se les llama bigotes. Los bigotes van desde los extremos de la caja hasta los
valores menor y mayor de los límites calculados en el paso 3.
5. Por último, mediante un asterisco se indica la localización de las observaciones atípicas.
DATOS BIVARIADOS
Son los valores de dos variables diferentes que se obtienen del mismo elemento poblacional.
Cada una de las dos variables puede ser cualitativa o cuantitativa. En consecuencia, tres combinaciones de
tipos de variable pueden formar datos bivariados:
1. Ambas variables son cualitativas (atributos).
2. Una variable es cualitativa (atributo) y la otra es cuantitativa (numérica).
3. Ambas variables son cuantitativas (ambas numéricas).
Dos variables cualitativas: tabla de doble entrada
Dos variables cuantitativas: Regresión lineal/diagrama de dispersión
Una variable cuantitativa – una variable cualitativa: multiples box-splot (según cuantas cuali tenga)
Dos variables cualitativas
Cuando resultan datos bivariados de dos variables cualitativas, es frecuente que los datos se ordenen en una
tabulación cruzada o tabla de contingencia.
Es frecuente que las tablas de contingencia muestren porcentajes. Estos porcentajes pueden basarse en toda
la muestra o en las clasificaciones de la submuestra.
Una variable cualitativa y una cuantitativa
Cuando resultan datos bivariados de una variable cualitativa y una cuantitativa, los valores cuantitativos se
ven como muestras separadas, con cada conjunto identificado por niveles de la variable cualitativa.

14
Dos variables cuantitativas
Cuando los datos bivariados son el resultado de dos variables cuantitativas, se acostumbra expresar
matemáticamente los datos como pares ordenados (x, y), donde x es la variable de entrada (a veces llamada
variable independiente) y y es la variable de salida (a veces llamada variable dependiente). Se dice que los
datos están ordenados porque un valor, x, siempre se escribe primero. Se llaman pareados porque para cada
valor de x siempre hay un valor correspondiente de y de la misma fuente. La variable de entrada x se mide o
controla para pronosticar la variable de salida y.
En problemas que se referen a dos variables cuantitativas, presentamos gráficamente los datos muestrales en
un diagrama de dispercion.
Diagrama de dispersión: es una gráfica de todos los pares ordenados de datos bivariados en un sistema de
ejes de coordenadas. La variable de entrada, x, se localiza en el eje horizontal, y la variable de salida, y, se
localiza en el eje vertical.
Nota: cuando construya un diagrama de dispersión, es conveniente construir escalas para que el rango de los
valores y, en todo el eje vertical, sea igual o ligeramente más corto que el rango de los valores x en todo el eje
horizontal. Esto crea una “ventana de datos” que es aproximadamente cuadrada.
El diagrama de dispersión muestra claramente que existe un patrón.
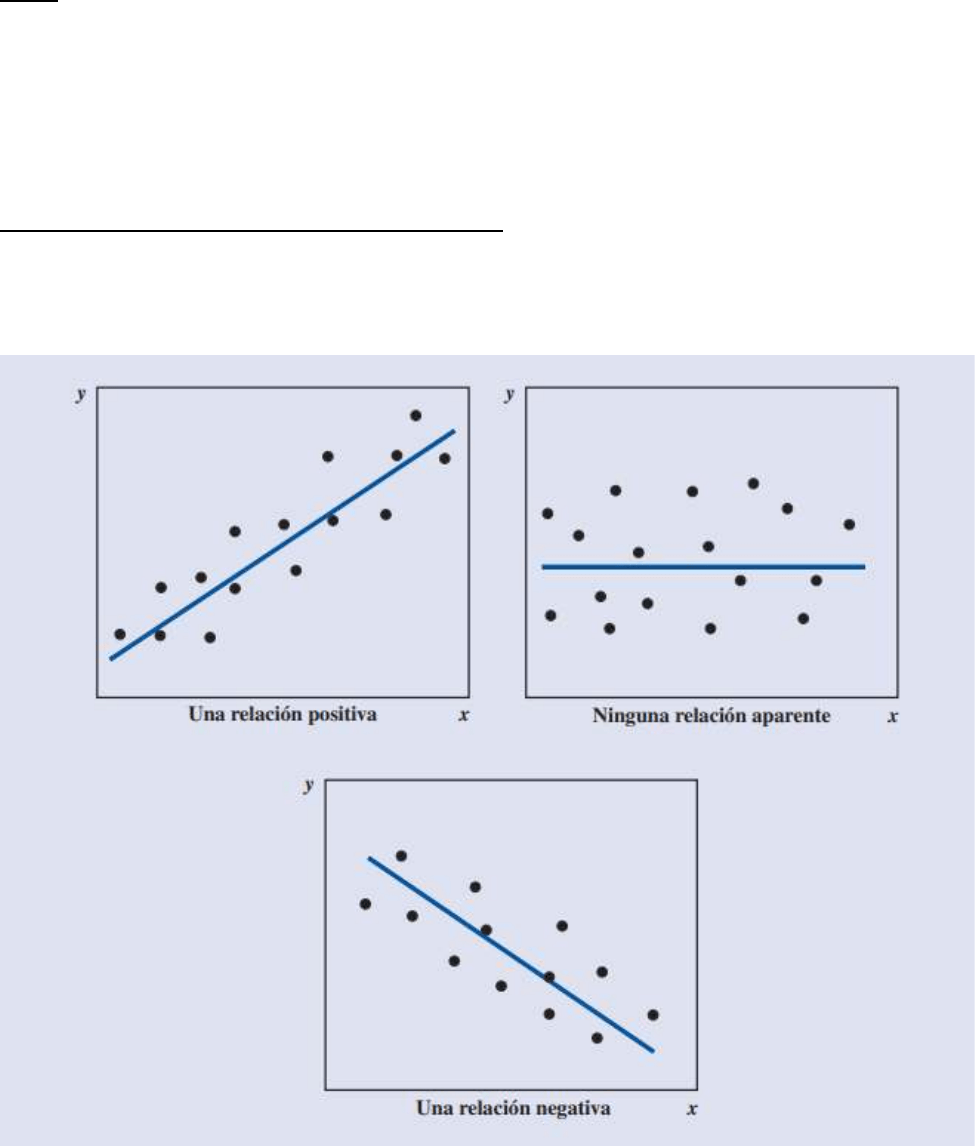
Correlación lineal
El objetivo principal del análisis de correlación lineal es medir la fuerza de una relación lineal entre dos
variables. Examinemos algunos diagramas de dispersión que demuestran diferentes relaciones entre entrada,
o variables independientes, x, y salida, o variables dependientes, y. Si cuando x aumenta no hay cambio
definido en los valores de y, decimos que no hay correlación, o no hay relación entre x y y. Si cuando x aumenta
hay un cambio en los valores de y, entonces hay una correlación. La correlación es positiva cuando y tiende a
aumentar y negativa cuando y tiende a disminuir. Si los pares ordenados (x, y) tienden a seguir una trayectoria
de línea recta, hay una correlación lineal. La precisión del cambio en y cuando x aumenta determina la fuerza
de la correlación lineal.
Se presenta una correlación lineal perfecta cuando todos los puntos caen exactamente en toda una recta, La
correlación puede ser positiva o negativa, dependiendo de si y aumenta o disminuye cuando x aumenta. Si los
datos forman una recta horizontal o vertical, no hay correlación porque una variable no tiene efecto en la otra.
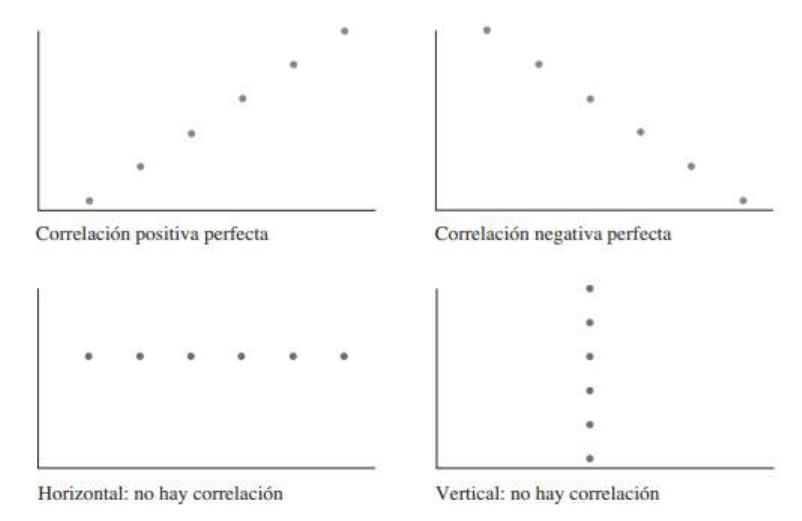
15
El coeficiente de correlación lineal, r, es la medida numérica de la fuerza de la relación lineal entre dos
variables. El coeficiente refleja la consistencia del efecto que un cambio en una variable tiene sobre la otra. El
valor del coeficiente de correlación lineal nos ayuda a contestar la pregunta: ¿hay correlación lineal entre las
dos variables bajo consideración? El coeficiente de correlación lineal, r, siempre tiene un valor entre –1 y +1.
Un valor de +1 significa una correlación positiva perfecta, y un valor de –1 muestra una correlación negativa
perfecta. Si cuando x aumenta hay un aumento general del valor de y, entonces r será positivo en valor.
En general, puede demostrar que si todos los valores del conjunto de datos caen en una línea recta con
pendiente positiva, el coeficiente de correlación será +1; es decir, un coeficiente de correlación de +1
corresponde a una relación lineal positiva perfecta entre x y y. Por otra parte, si los puntos del conjunto de
datos caen sobre una línea recta con pendiente negativa, el coeficiente de correlación muestral será -1; un
coeficiente de correlación de -1 corresponde a una relación lineal negativa perfecta entre x y y.
Suponga ahora que un conjunto de datos muestra una relación lineal positiva entre x y y, pero que la relación
no es perfecta. El valor de rxy será menor a 1, indicando que no todos los puntos del diagrama de dispersión
se encuentran en una línea recta. Entre más se desvíen los puntos de una relación lineal positiva perfecta, más
pequeño será rxy. Si rxy es igual a cero, entonces no hay relación lineal entre x y y; si rxy tiene un valor cercano
a cero, la relación lineal es débil.
Que la correlación entre dos variables sea alta no significa que los cambios en una de las variables ocasionen
modificaciones en la otra.
Causalidad y variables ocultas
Uno puede enfocarse en una situación, el efecto, y tratar de determinar su causa(s), o puede empezar con una
causa y discutir su efecto(s). Para determinar la causa de algo, nos preguntamos por qué ocurrió. Para
determinar el efecto, nos preguntamos qué pasó.
Variable oculta: es una variable no incluida en un estudio pero que tiene un efecto sobre las variables del
estudio y hace parecer que esas variables están relacionadas.
Este documento contiene más páginas...
Descargar Completo
Resumen_kWAdK41.pdf
 Estamos procesando este archivo...
Estamos procesando este archivo...
 Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Descargar
Estamos procesando este archivo...
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.