
12
Capítulo
Expresión y regulación de los genes
Aunque fue diagnosticado a temprana edad con fibrosis quís-
tica, Grégory Jean-Paul Lemarchal esperaba que “cuando la gente
escuchara la música, se diera cuenta de que era un cantante y
compositor que por casualidad estaba enfermo”.
Estudio de caso
Fibrosis quística
SI TODO LO QUE CONOCIERAS de él fuera su música,
pensarías que Grégory Jean-Paul Lemarchal alcanzó
el éxito: un joven cantante y compositor que saltó a
la fama al ganar en 2003 el programa musical “Star
Academy” en Francia, que lo llevó a firmar un contrato
de grabación con Universal Music Group. Pero la
genética le endilgó un revés por partida doble: dos
copias de un alelo recesivo defectuoso que codifica
una proteína crucialmente importante llamada CFTR.
Lemarchal, lo mismo que unos 30 mil estadounidenses,
tres mil canadienses y 20 mil europeos, tenía fibrosis
quística. Antes de la moderna atención médica, la
mayoría de la gente con fibrosis quística moría a los
cuatro o cinco años; todavía hoy, la esperanza de vida
promedio es de 35 a 40 años.
La CFTR es una proteína de canal que es permeable
al cloro y se encuentra en muchas partes del
cuerpo, como glándulas sudoríparas, pulmones e
intestinos. Veamos su función en la transpiración.
Cuando las glándulas de partes profundas de la
piel producen el sudor, éste contiene muchas sales
(cloruro de sodio), aproximadamente tantas como
la sangre. Pero casi todas estas sales se recuperan
a medida que el sudor pasa por los conductos que
llevan de las células productoras a la superficie
de la piel. Los investigadores no entienden por
completo el mecanismo, pero se requiere la CFTR
para la reabsorción del cloro y el sodio. Entonces, las
mutaciones en el gen CFTR producen proteínas CFTR
defectuosas que impiden la reabsorción del cloro y el
sodio, así que estas sales se quedan en el sudor.
El sudor salino en general no es muy perjudicial,
pero lamentablemente, las células que revisten las
vías respiratorias de los pulmones tienen las mismas
proteínas CFTR. Generalmente, las vías respiratorias
están recubiertas por una capa delgada de moco aguado,
que atrapa bacterias y desechos. Proteínas que son
“antibióticos naturales” en el líquido matan muchas
bacterias que luego son expulsadas de los pulmones
por los cilios del revestimiento celular de dichas vías.
Las proteínas CFTR defectuosas hacen que el moco
se “deshidrate” y que se espese tanto que los cilios
no pueden desalojarlo de los pulmones. Por tanto, las
vías respiratorias quedan parcialmente obstruidas y las
bacterias se multiplican, causando infecciones pulmonares
crónicas. Las personas con fibrosis quística tosen a
menudo, tratando de despejarlas. Grégory Lemarchal
pensaba que la tos fortaleció sus cuerdas vocales y le
ayudaba a producir su tono fuerte y profundo.
En este capítulo se examinarán los procesos por los
cuales las instrucciones de los genes se convierten en
proteínas. Cuando un gen muta, ¿qué efecto tiene
en la estructura y función de la proteína codificada,
como la CFTR? ¿Por qué diferentes mutaciones del
mismo gen tienen consecuencias distintas?
218 UNIDAD 2 Herencia
De un vistazo
12.1
¿CÓMO SE UTILIZA LA INFORMACIÓN
DEL ADN EN LA CÉLULA?
La información, por sí misma, no hace nada. Por ejemplo, un pla-
no puede describir la estructura de una casa con gran detalle, pero
si los trabajadores no transforman esa información en acción, no
existirá ninguna casa. Del mismo modo, aunque la secuencia de
bases del ADN —el “plano molecular” de toda célula— contiene
una cantidad increíble de información, el ADN por sí mismo no
puede realizar ninguna acción. Entonces, ¿cómo determina el ADN
si tienes cabello negro, rubio o rojo o si tienes pulmones normales
o con fibrosis quística?
La mayoría de los genes contiene la información
necesaria para la síntesis de una sola proteína
Mucho antes de que se descubriera que los genes están hechos de
ADN, los biólogos trataron de determinar cómo es que los genes
afectan el fenotipo de las células de organismos enteros. A partir
de los estudios sobre la herencia de trastornos metabólicos en se-
res humanos a comienzos del siglo XX —los cuales culminaron
con una serie de experimentos brillantes con moho de pan común
en la década de 1940—, los biólogos descubrieron que casi todos
los genes contienen la información necesaria para dirigir la síntesis
de una sola proteína (véase la sección “Investigación científica: Un
gen, una proteína” en las páginas 220-221). Las proteínas son los
“trabajadores moleculares” de la célula, que construyen muchas de
sus estructuras celulares y las enzimas que catalizan sus reacciones
químicas. Por tanto, debe existir un flujo de información del ADN
a las proteínas.
El ADN proporciona las instrucciones
para la síntesis de las proteínas
a través de intermediarios ARN
El ADN de una célula eucarionte se alberga en el núcleo, pero
la síntesis de las proteínas ocurre en los ribosomas del citoplas-
ma (véanse las páginas 66-67). Por tanto, el ADN no puede guiar
directamente la síntesis de proteínas: necesita un intermediario,
una molécula que lleve la información del ADN del núcleo a los
ribosomas del citoplasma. Esta molécula es el ácido ribonuclei-
co, o ARN.
El ARN es parecido al ADN pero tiene tres diferencias es-
tructurales: (1) tiene usualmente una sola hebra, (2) tiene el azú-
car ribosa en lugar de desoxirribosa en la hebra, y (3) tiene la base
uracilo en lugar de la base timina (
Tabla 12-1).
El ADN codifica la síntesis de muchos tipos de ARN, tres
de los cuales cumplen funciones específicas en la síntesis de
proteínas: ARN mensajero (ARNm), ARN ribosómico (ARNr)
y ARN de transferencia (ARNt) (
FIGURA 12-1). Existen otros
tipos de ARN, como el ARN que usan como material genético
algunos virus, como el VIH; ARN enzimático, llamado ribozima,
que cataliza diversas reacciones incluyendo la separación de las
Estudio de caso Fibrosis quística
12.1 ¿Cómo se utiliza la información del ADN
en la célula?
La mayoría de los genes contiene la información necesaria
para la síntesis de una sola proteína
El ADN proporciona las instrucciones para la síntesis de las
proteínas a través de intermediarios ARN
Investigación científica Un gen, una proteína
Resumen: la información genética se transcribe en el ARN
y se traduce en proteínas
El código genético usa tres bases para especificar un
aminoácido
12.2 ¿Cómo se transcribe la información de un gen
en ARN?
La transcripción comienza cuando la ARN polimerasa se
enlaza al promotor de un gen
La elongación produce una cadena de ARN alargada
La transcripción se detiene cuando la ARN polimerasa llega
a la señal de terminación
12.3 ¿Cómo se transcribe la secuencia de bases
del ARN mensajero en proteínas?
La síntesis del ARN mensajero difiere entre procariontes
y eucariontes
Guardián de la salud: Genética, evolución y medicina
En la traducción, el ARNm, el ARNt y los ribosomas
cooperan para sintetizar proteínas
Estudio de caso continuación Fibrosis quística
Protein Synthesis (disponible en inglés)
12.4 ¿Cómo afectan las mutaciones el
funcionamiento de las proteínas?
Las mutaciones pueden tener diversos efectos en la
estructura y funcionamiento de las proteínas
Las mutaciones producen la materia prima de la evolución
Estudio de caso continuación Fibrosis quística
12.5 ¿Cómo se regulan los genes?
Regulación de los genes en los procariontes
Regulación de los genes en los eucariontes
Las células eucariontes regulan la transcripción de genes
individuales, regiones de cromosomas o cromosomas
completos
Investigación científica ARN, ya no es un simple
mensajero
Guardián de la salud Sexo, envejecimiento y
mutaciones
Estudio de caso otro vistazo Fibrosis quística
Expresión y regulación de los genes Capítulo 12 219
moléculas del ARN; y dos tipos de ARN que más adelante abor-
daremos brevemente: ARN Xista, que evita que se use la mayor
parte de la información genética de uno de los cromosomas X
de los mamíferos hembra (véase la sección 12.5) y microARN,
que cumple la función de regular el desarrollo y el combate
de las enfermedades (véase la sección “Investigación científica:
ARN, ya no es un simple mensajero” de la página 234). Aquí
nos enfocaremos en las funciones del ARNm, ARNr y ARNt en
la síntesis de las proteínas.
El ARN mensajero transporta el código de la síntesis de
proteínas del ADN a los ribosomas
El ARN mensajero lleva el código de la secuencia de aminoácidos
de una proteína del ADN a los ribosomas, los cuales sintetizan la
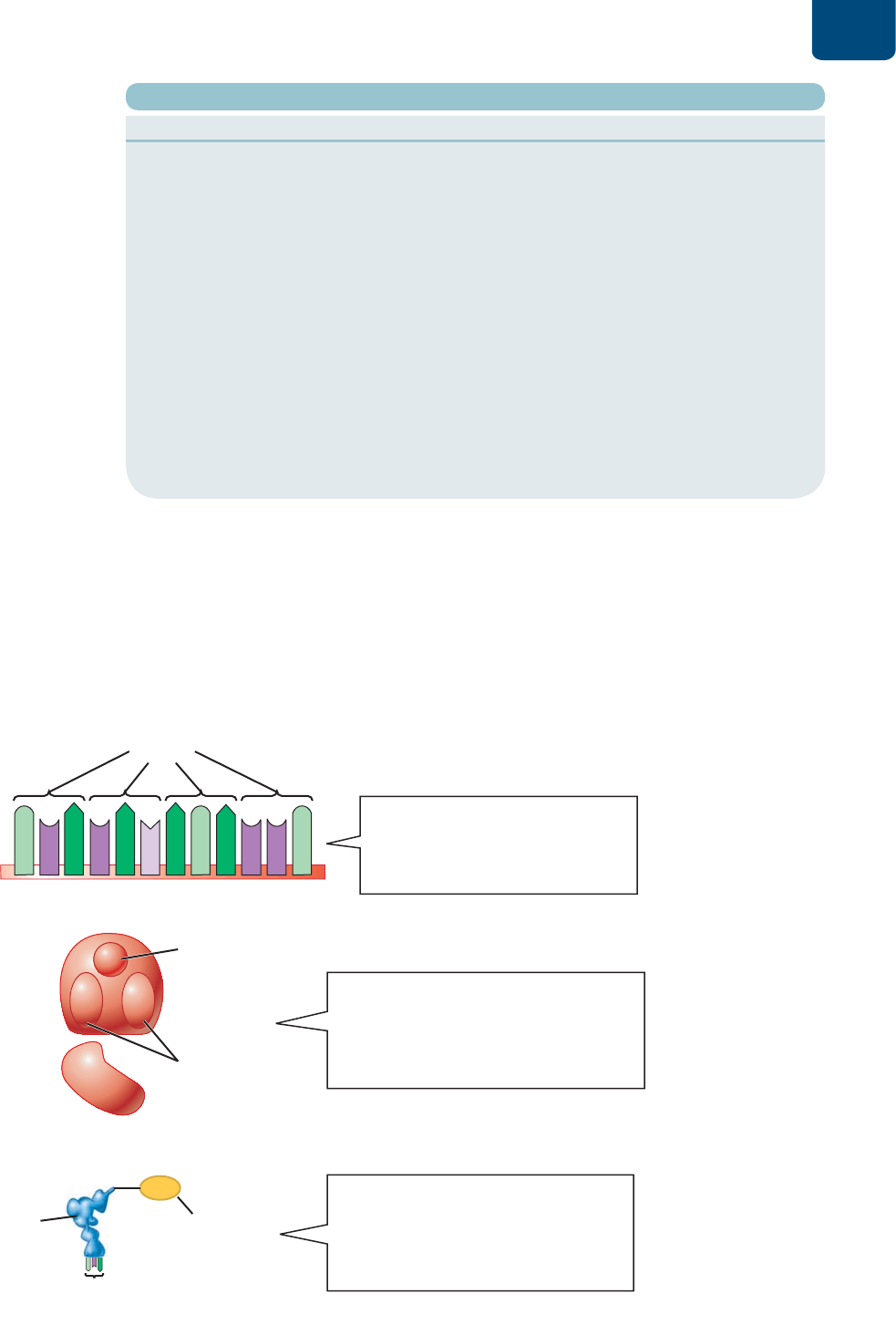
9PIVZVTH!JVU[PLUL(95YPIVZ}TPJV(95Y
J(95KL[YHUZMLYLUJPH(95[
VXEXQLGDG
PD\RU
$51W
6LWLRVGHHQODFHGH
$51WDPLQRÀFLGRV
VLWLRGHFDWÀOLVLV
FRGRQHV
DPLQRÀFLGR
XQLGR
DQWLFRGʼnQ
VXEXQLGDG
PHQRU
H(95TLUZHQLYV(95T
/DVHFXHQFLDGHEDVHVGHO$51POOHYD
ODLQIRUPDFLʼnQSDUDODVHFXHQFLDGH
DPLQRÀFLGRVGHXQDSURWHķQDORV
JUXSRVGHHVWDVEDVHVOODPDGDV
FRGRQHVHVSHFLILFDQORVDPLQRÀFLGRV
(O$51UVHFRPELQDFRQSURWHķQDVSDUD
IRUPDUULERVRPDVODVXEXQLGDGPHQRUVH
HQOD]DFRQHO$51P/DVXEXQLGDGPD\RU
VHHQOD]DFRQHO$51W\FDWDOL]DODIRUPDFLʼnQ
GHHQODFHVSHSWķGLFRVHQWUHORVDPLQRÀFLGRV
GXUDQWHODVķQWHVLVGHSURWHķQDV
&DGD$51UOOHYDXQDPLQRÀFLGRHVSHFķILFR
HQHVWHHMHPSORODWLURVLQD>W\U@DXQ
ULERVRPDGXUDQWHODVķQWHVLVGHSURWHķQDV
HODQWLFRGʼnQGHO$51WVHHPSDUHMDFRQXQ
FRGʼnQGHO$51PSDUDTXHHODPLQRÀFLGR
FRUUHFWRVHLQFRUSRUHDODSURWHķQD
I
W\U
*$*8$&*$*888
FIGURA 12-1 Las células sintetizan
tres tipos principales de ARN que
se requieren para la síntesis de las
proteínas
Tabla 12-1 Comparación del ADN y el ARN
ADN ARN
Hebras 2 1
Azúcar Desoxirribosa Ribosa
Tipos
de bases
adenina (A), timina (T) adenina (A), uracilo (U)
citosina (C), guanina (G) citosina (C), guanina (G)
Pares
de bases
ADN-ADN
ARN-ADN
ARN-ARN
A-T A-T
A-U
T-A U-A
U-A
C-G C-G
C-G
G-C G-C
G-C
Función
Contiene genes: la secuencia de las bases
en la mayor parte de los genes determina
la secuencia de aminoácidos de una
proteína
ARN mensajero (ARNm): transporta el
código del gen codificador de proteínas
del ADN a los ribosomas
ARN ribosómico (ARNr): se combina con
proteínas para formar ribosomas, las
estructuras que enlazan los aminoácidos
para formar una proteína
ARN de transferencia (ARNt): lleva los
aminoácidos a los ribosomas

220 UNIDAD 2 Herencia
Investigación científica
Un gen, una proteína
En el capítulo 10 se estudió que los genes pueden determinar o
cuando menos influir en rasgos tan diferentes como la textura del
pelo y el color de las flores o heredar enfermedades como la anemia
de células falciformes. Pero, ¿cómo? Así como Mendel descubrió los
principios de la herencia con las plantas de chícharos comestibles
como un “sistema modelo” comprensible, biólogos posteriores
trataron de averiguar cómo funcionan los genes usando sistemas
modelos con fenotipos claros y fáciles de medir. Estos
sistemas modelo fueron las vías metabólicas por los cuales las
células sintetizan moléculas complejas (véanse las páginas 105-106).
Muchas vías metabólicas sintetizan moléculas en una serie de
pasos concatenados que catalizan, cada uno, una enzima proteica
específica. En una vía metabólica, el producto de una enzima se
convierte en el sustrato de la siguiente, como una línea de montaje
molecular (véase la figura 6-12). ¿Cómo codifican los genes la
información necesaria para producir estas rutas?
La primera pista se obtuvo de bebés que nacieron con
vías metabólicas deficientes. Por ejemplo, los defectos en el
metabolismo de dos aminoácidos, como la fenilalanina y
la tirosina, pueden causar albinismo (falta de pigmentación en la
piel o el pelo; véase la figura 10-22) o diversas enfermedades con
síntomas tan variados como orina que se vuelve marrón cuando
se expone al aire (alcaptonuria) o acumulación de fenilalanina en
el cerebro, que causa retraso mental (fenilcetonuria). A principios
de la década de 1900, el médico inglés Archibald Garrod estudió la
herencia de estos errores congénitos del metabolismo. Formuló las
hipótesis de que (1) estos errores fueron causados por una versión
defectuosa de una enzima; (2) cada enzima defectuosa es causada
por un alelo defectuoso de un único gen, y (3) por consiguiente,
cuando menos algunos genes deben codificar la información
necesaria para la síntesis de las proteínas.
Dada la tecnología de aquel entonces y las limitaciones de los
estudios genéticos humanos, Garrod no pudo probar de forma
concluyente sus hipótesis y fueron ignoradas en gran medida.
Sin embargo, a inicios de la década de 1940, los genetistas
George Beadle y Edward Tatum tomaron las vías metabólicas de
un moho de pan común, Neurospora crassa, para demostrar que
Garrod tenía razón.
Aunque normalmente encontramos el crecimiento de la
Neurospora en pan duro, este moho puede sobrevivir con una
dieta mucho más simple. Lo único que necesita es una fuente
de energía, como carbohidratos, algunos minerales y vitamina
B
6
. Por tanto, la Neurospora elabora las enzimas necesarias para
hacer prácticamente todas sus moléculas orgánicas, incluyendo
aminoácidos (en contraste, los seres humanos no podemos
sintetizar muchas vitaminas ni nueve de los 20 aminoácidos
comunes; tenemos que obtenerlos de los alimentos). Beadle
y Tatum usaron la Neurospora para someter a prueba su
hipótesis de que muchos de los genes de un organismo codifican
información necesaria para sintetizar enzimas.
Si la hipótesis era correcta, una mutación en un gen
particular trastornaría la síntesis de una enzima concreta, lo
que suspendería una de las vías metabólicas del moho. Así,
un moho mutante no podría sintetizar parte de sus moléculas
orgánicas, como los aminoácidos, que necesita para sobrevivir.
La Neurospora mutante crece en un medio ambiente simple de
carbohidratos, minerales y vitamina B
6
, sólo si se le suministran
las moléculas orgánicas faltantes.
Beadle y Tatum indujeron mutaciones exponiendo la
Neurospora a rayos X y luego estudiaron la herencia de las vías
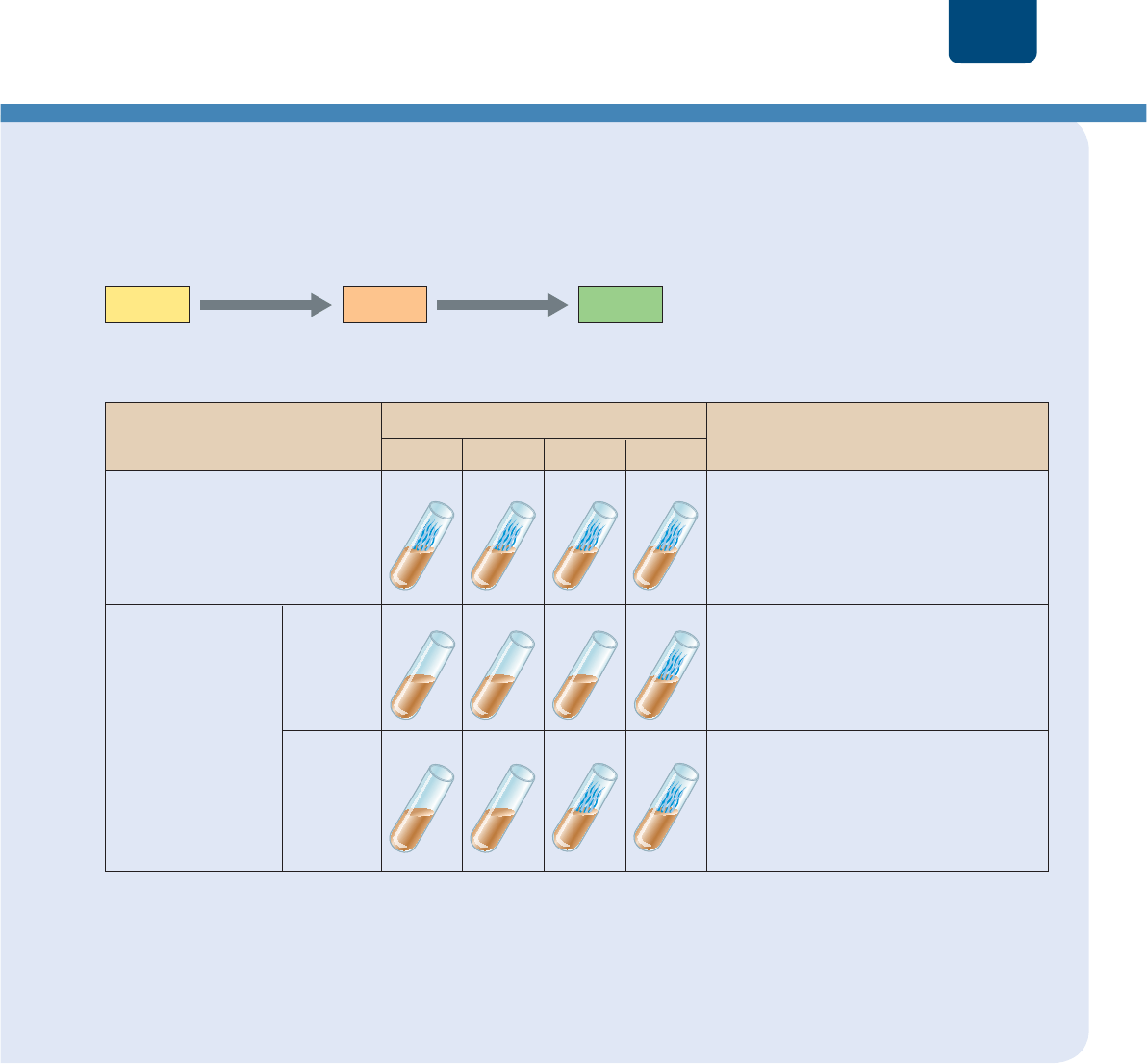
metabólicas que sintetizan el aminoácido arginina (FIGURA E12-1).
En los mohos normales, la arginina se sintetiza a partir de la
citrulina, la cual es sintetizada por la ornitina (FIGURA E12-1a).
El mutante A crecía únicamente si recibía un complemento de
arginina, pero no con un complemento de citrulina ni ornitina
(FIGURA E12-1b). Por tanto, esta hebra tenía un defecto en la
enzima que convierte la citrulina en arginina. El mutante B sólo
crecía si se le suministraba arginina o citrulina, pero no si se le
suministraba ornitina (véase la figura E12-1b). Este mutante tenía
un defecto en la enzima que convertía la ornitina en citrulina.
Como una mutación de un único gen afecta nada más a una
enzima de una sola vía metabólica, Beadle y Tatum concluyeron
que un gen codifica la información de una enzima. La importancia
de esta observación fue reconocida en 1958 con un premio Nobel,
que Beadle y Tatum compartieron con Joshua Linderberg, uno de
los estudiantes de Tatum.
Casi todas las enzimas son proteínas, pero muchas proteínas
no son enzimas. Por ejemplo, la queratina es una proteína
estructural de pelo y uñas, pero no cataliza ninguna reacción
química. Además, muchas enzimas están compuestas por más
de una unidad proteica. Por ejemplo, la ADN polimerasa consta de
más de una docena de proteínas. Así, la relación “un gen, una
enzima” propuesta por Beadle y Tatum fue corregida como “un
gen, una proteína”.
proteína especificada por la secuencia de bases del ARNm (FIGU-
RA 12-1a
). En las células eucariontes, el ADN queda guardado de
modo seguro en el núcleo, tal como un documento valioso en una
biblioteca; mientras que el ARNm, como una fotocopia molecular,
lleva la información del citoplasma que se va a usar en la síntesis de
proteínas. Como veremos pronto, grupos de tres bases del ARNm,
llamadas codones, especifican qué aminoácidos se van a incorporar
a la proteína.
El ARN ribosómico y las proteínas forman ribosomas
Los ribosomas son estructuras que realizan la traducción, están
compuestos de ARNr y muchas proteínas diferentes. Cada ribo-
soma consta de dos subunidades: una pequeña y una grande. La
subunidad menor tiene sitios de enlace para el ARNm, un ARNt de
inicio (metionina; véase en la siguiente sección la descripción del
ARNt) y otras proteínas que forman colectivamente el “comple-
jo de preiniciación”, que es esencial para ensamblar el ribosoma
y comenzar la síntesis de las proteínas (véase la figura 12-7 ❶).
La subunidad mayor tiene sitios de enlace para dos moléculas de
ARNt y un sitio catalítico para unir los aminoácidos unidos a las
moléculas de ARNt. Salvo que sean proteínas activas de síntesis,
las dos subunidades quedan separadas (
FIGURA 12-1b). En la sín-
tesis de proteínas, las subunidades se unen y constriñen entre ellas
una molécula de ARNm (véase la figura 12-7 ❸).
Expresión y regulación de los genes Capítulo 12 221
(Como recordarás del capítulo 3, una proteína es una cadena de
aminoácidos unidos por enlaces peptídicos. Dependiendo de su
longitud, las proteínas pueden llamarse péptidos [cadenas cortas]
o polipéptidos [cadenas largas]. En este texto, normalmente
llamamos a toda cadena de aminoácidos, independientemente
de su tamaño, péptido de proteínas.) Hay excepciones a
la regla “un gen, una proteína”, entre ellas varias en las
que el producto final de un gen no es proteína, sino ácido
ribonucleico (ARN). Sin embargo, casi todos los genes
codifican la secuencia de aminoácidos de una proteína.
Complementos agregados al medio
ninguno
ornitina
enzima 1
gen B gen A
enzima 2
argininacitrulina
(b) Crecimiento de Neutrospora normal y genes mutantes en un medio simple, con diferentes complementos
(a) Vía metabólica para sintetizar el aminoácido arginina
La Neurospora normal sintetiza
arginina, citrulina y ornitina.
Conclusiones
El gen mutante A crece únicamente si se
añade arginina. No puede sintetizar la
arginina porque tiene un defecto en
la enzima 2; se necesita el gen A para
sintetizar la arginina.
A
B
Mutantes con un
gen defectuoso
argininacitrulinaornitina
El gen mutante B crece si se agregan
arginina y citrulina. No puede sintetizar
arginina porque tiene un defecto en la
enzima 1. Se requiere el gen B para
sintetizar la citrulina.
Neurospora normal
Genotipo de Neurospora
FIGURA E12-1 Experimentos de Beadle y Tatum con genes mutantes de Neurospora (a) Cada
paso de la vía metabólica de la síntesis de arginina es catalizada por una enzima diferente. (b) Al analizar qué
complementos favorecen el crecimiento de los mohos mutantes en medio de nutrimentos simples, Beadle y
Tatum concluyeron que un único gen codifica la síntesis de una sola enzima.
PREGUNTA ¿Qué resultado esperarías de un mutante que no tiene una enzima necesaria para producir
ornitina?
El ARN de transferencia transporta
aminoácidos a los ribosomas
El ARN de transferencia entrega los aminoácidos apropiados al
ribosoma, para que se incorporen en una proteína. Cada célula
sintetiza por lo menos un ARNt (y a veces varios) por cada ami-
noácido. Veinte enzimas del citoplasma, una por cada aminoáci-
do, reconocen las moléculas del ARNt y usan energía del ATP para
unir el aminoácido correcto a un extremo (
FIGURA 12-1c). Estas
moléculas de ARNt “cargadas” transportan sus aminoácidos a un
ribosoma. Un grupo de tres bases, llamado anticodón, se proyecta
de cada ARNt. El emparejamiento de bases complementarias entre
codones de ARNm y anticodones de ARNt dirige los aminoácidos
correctos que se van a utilizar para sintetizar una proteína (véase la
sección 12.3).
Resumen: la información genética se transcribe
en el ARN y se traduce en proteínas
La información del ADN se usa para dirigir la síntesis de proteínas
en dos procesos llamados transcripción y traducción (
FIGURA 12-2
y
Tabla 12-2).
1. En la transcripción (FIGURA 12-2a), la información con-
tenida en el ADN de un gen particular es copiada
en el ARN mensajero (ARNm), ARN de transferencia
(ARNt) o el ARN ribosómico (ARNr). Así, un gen es un
segmento de ADN que puede ser copiado o transcrito en
ARN. En las células eucariontes, la transcripción ocurre
en el núcleo.

222 UNIDAD 2 Herencia
H;YHUZJYPWJP}U
/DWUDGXFFLʼnQGHO$51P
SURGXFHXQDSURWHķQDFRQ
XQDVHFXHQFLDGHDPLQRÀFLGRV
GHWHUPLQDGDSRUODVHFXHQFLD
GHQXFOHʼnWLGRVHQHO$51P
I;YHK\JJP}U
/DWUDQVFULSFLʼnQGHO
JHQSURGXFHXQ$51P
FRQXQDVHFXHQFLDGH
QXFOHʼnWLGRV
FRPSOHPHQWDULDGHXQD
GHODVKHEUDVGHO$'1
$'1
$51PHQVDMHUR
SURWHķQD
ULERVRPD
JP[VWSHZTH
UJSLV
JHQ
FIGURA 12-2 La información genética pasa del ADN al
ARN y las proteínas (a) En la transcripción, la secuencia de
nucleótidos de un gen especifica una secuencia de nucleótidos de
una molécula de ARN complementario. Para los genes que codifican
genes, el producto es una molécula de ARNm que sale del núcleo
y entra en el citoplasma. (b) En la traducción, la secuencia en una
molécula de ARNm que especifica la secuencia de aminoácidos de
una proteína.
2. La secuencia de bases del ARNm codifica la secuencia de
aminoácidos de una proteína. En la síntesis de proteínas,
o traducción (
FIGURA 12-2b), se descifra esta secuen-
cia de bases de ARNm. El ARN ribosómico se combina
con docenas de proteínas para formar un ribosoma. Las
moléculas de ARN de transferencia llevan los aminoácidos
al ribosoma. El ARN mensajero se enlaza al ribosoma,
donde el emparejamiento de bases entre el ARNm y el ARNt
convierte la secuencia de bases del ARNm en la secuencia de
aminoácidos de una proteína. En las células eucariontes, los
ribosomas se encuentran en el citoplasma y, por tanto, ahí
también ocurre la traducción.
Es fácil confundir los términos transcripción y traducción.
Comparar su significado común en español con el significado en
biología será útil para recordar la diferencia. En castellano, “trans-
cribir” significa hacer una copia escrita de algo, casi siempre en el
mismo idioma. Por ejemplo, en los tribunales de muchos países,
los testimonios ofrecidos de palabra se transcriben en un documen-
to por escrito; tanto el testimonio como el texto están en el mismo
idioma. En biología, la transcripción es el acto de copiar informa-
ción del ADN en el ARN con el “idioma” común de los nucleótidos.
En cambio, el significado común en castellano de “traducción” es el
paso de un registro a otro, como cuando se interpretan las palabras
de un idioma para escribirlas en las de otro. En biología, la traduc-
ción consiste en convertir la información del “idioma nucleótido”
del ARN al “idioma aminoácido” de las proteínas.
El código genético usa tres bases
para especificar un aminoácido
Investigaremos con mayor detalle la transcripción y la traducción
en las secciones 12.2 y 12.3. Ahora, revisemos la forma en que los
genetistas derribaron la barrera del idioma: ¿cómo se traduce el
lenguaje de las secuencias de nucleótidos del ADN y el ARN men-
sajero en el lenguaje de las secuencias de aminoácidos de las pro-
teínas? Esta “traducción” depende de un “diccionario” llamado
código genético.
El código genético traduce la secuencia de las bases de
los ácidos nucleicos a la secuencia de aminoácidos de las proteí-
nas. ¿Qué combinaciones de bases codifican cuáles aminoácidos?
Tanto el ADN como el ARN contienen cuatro bases diferentes:
A, T (o U en el ARN), G y C (véase la Tabla 12-1). Sin embargo,
las proteínas están compuestas por 20 aminoácidos diferentes, de
modo que una base no puede codificar un aminoácido: no hay
suficientes bases. Si una secuencia de dos bases codifica un ami-
noácido, habría 16 posibles combinaciones (las cuatro primeras
bases emparejadas con las cuatro segundas bases: 4 4 16).
Todavía no es suficiente para codificar los 20 aminoácidos. Una
tercera secuencia de bases resulta en 64 posibles combinaciones
4 4 4 64), que es más que suficiente. A partir de este ejerci-
cio matemático, el físico George Gamow formuló la hipótesis de
que tres bases especifican un aminoácido. En 1961, Francis Crick
y tres colaboradores demostraron que la hipótesis es correcta.
Para entender cualquier idioma, sus hablantes deben sa-
ber lo que significan las palabras, dónde comienzan y dónde ter-
minan, y dónde se inician y acaban las frases. Para descifrar las
“palabras” del código genético, Marshall Niremberg y Heinrich
Matthaei cultivaron bacterias y aislaron los componentes necesa-
rios para sintetizar las proteínas. A esta mezcla agregaron ARNm,
con lo que pudieron controlar qué “palabras” habían de tradu-
cirse. Podían ver qué aminoácidos se incorporaban a las proteí-
nas. Por ejemplo, una hebra de ARNm compuesta enteramente
de uracilo (UUUUUUUU...) dirigía la mezcla para sintetizar una
proteína formada exclusivamente por el aminoácido fenilalanina.
Tabla 12-2
Transcripción y traducción
Proceso
Información
para el proceso Producto
Enzima principal o
estructura involucrada
en el proceso Par de bases requeridas
Transcripción
(síntesis de ARN)
Un segmento de una
hebra de ADN
Una molécula de ARN (por
ejemplo, ARNm, ARNt o
ARNr)
ARN polimerasa ARN con ADN; las bases del ARN se
emparejan con las bases del ADN al
sintetizar una molécula de ARN
Traducción
(síntesis de una proteína)
ARNm Una molécula de proteína Ribosomas (también
requiere ARNt)
ARNm con ADN: un codón de ARNm forma
pares de bases con el anticodón del
ARNt

Expresión y regulación de los genes Capítulo 12 223
Por consiguiente, el triplete UUU debe especificar la fenilalani-
na. Como el código genético fue descifrado por medio de estos
ARNm artificiales, normalmente se escribe con tripletes de bases
en el ARNm (más que el ADN) que codifican cada aminoácido
(
Tabla 12-3). Estos tripletes de ARNm se llaman codones.
¿Qué pasa con la puntuación? ¿Cómo reconoce una célula
dónde empiezan y dónde terminan los codones? La traducción
comienza con el codón AUG, llamado adecuadamente codón de
inicio. Como AUG codifica también el aminoácido metionina,
todas las proteínas comienzan con metionina (aunque puede ser
retirado después de sintetizar la proteína). Tres codones (UAG,
UAA y UGA) son codones de término o de alto. Cuando el
ribosoma encuentra un codón de término, libera la proteína re-
cién sintetizada y el ARNm. Como todos los codones constan de
tres bases y se especifican el principio y el final de una proteína,
no hace falta agregar puntuación (“espacios”) entre los codones.
¿Por qué? Consideremos lo que ocurriría si en castellano sólo hu-
biera palabras con tres letras; una frase como VANLOSDOSPOR-
PAN sería perfectamente comprensible, aun sin espacios entre las
palabras.
Puesto que el código genético tiene tres codones de térmi-
no, quedan 61 tripletes de nucleótidos para especificar sólo 20
aminoácidos. Así, casi todos los aminoácidos están especificados
por varios codones; por ejemplo, seis codones (UUA, UUG, CUU,
CUC, CUA y CUG) especifican la leucina (véase la Tabla 12-3).
Sin embargo, cada codón especifica un, y sólo un, aminoácido.
UUA especifica siempre la leucina, nunca isoleucina, glicina ni
ningún otro aminoácido.
¿Cómo dirigen los codones la síntesis de proteínas? Desci-
frar los codones del ARNm es tarea del ARNt y de los ribosomas.
Recuerda que el ARNt transporta los aminoácidos a los riboso-
mas y que hay moléculas peculiares de ARNt que llevan cada tipo
diferente de aminoácido. Cada uno de estos ARNt exclusivos tie-
ne tres bases expuestas, llamadas anticodones, que son comple-
mentarios de las bases de un codón en el ARNm. Por ejemplo,
el codón del ARNm GUU forma pares de bases con el anticodón
CAA o un ARNt que tiene el aminoácido valina unido a su ex-
tremo. Como veremos en la sección 12.3, un ribosoma puede
entonces incorporar la valina a una cadena de aminoácidos en
crecimiento.
12.2
¿CÓMO SE TRANSCRIBE LA
INFORMACIÓN DE UN GEN EN ARN?
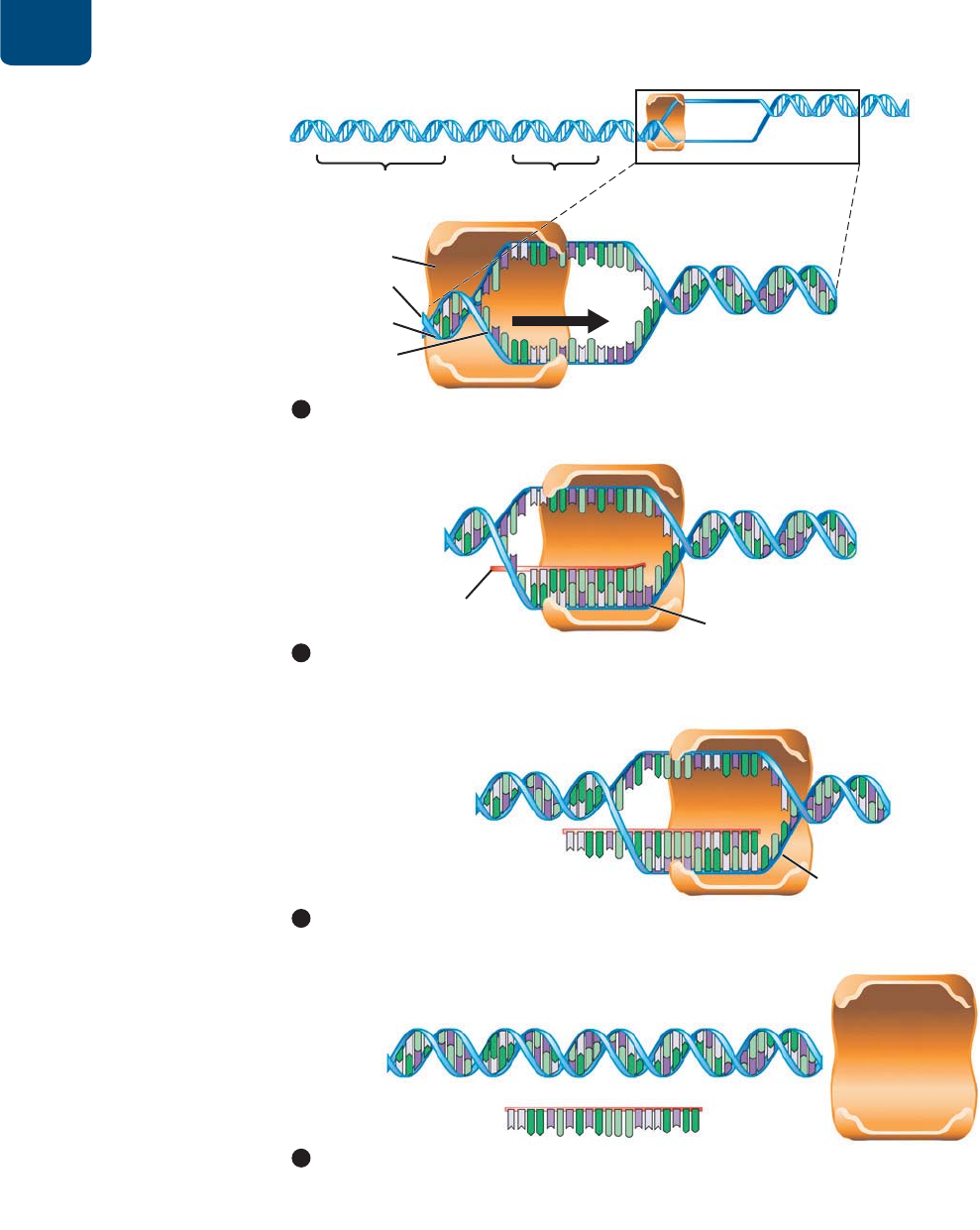
La transcripción (FIGURA 12-3) consta de tres etapas: (1) inicia-
ción, (2) elongación y (3) terminación. Estas tres etapas correspon-
den a las tres partes principales de casi todos los genes de euca-
riontes y procariontes: (1) una región promotora al inicio del gen,
donde comienza la transcripción, (2) el “cuerpo” del gen, donde
ocurre la elongación de la hebra de ARN, y (3) una señal de termi-
nación al final del gen, donde se concluye la síntesis del ARN.
La transcripción comienza cuando la ARN
polimerasa se enlaza al promotor de un gen
La enzima ARN polimerasa sintetiza el ARN. Para iniciar la trans-
cripción, la ARN polimerasa debe localizar primero el comienzo
de un gen. Cerca del comienzo de todo gen hay una secuencia sin
transcribir de ADN llamada promotor. En las células eucariontes,
un promotor consta de dos regiones principales: (1) una secuencia
corta de bases, muchas veces TATAAA, que enlaza la ARN polime-
rasa, y (2) una o más secuencias diferentes, llamadas sitios de enla-
ce de los factores de transcripción o elementos de respuesta. Cuan-
do ciertas proteínas celulares, llamadas factores de transcripción, se
unen a uno de estos sitios de enlace, refuerzan o suprimen el enlace
de la ARN polimerasa con el promotor y, así, refuerzan o suprimen
la transcripción de un gen. Regresaremos a este importante tema
de la regulación de los genes en la sección 12.5.
Primera base
Tercera base
Tabla 12-3 Código genético (codones de ARNm)
Segunda base
U
C
A
G
U
UUU Fenilalanina (Phe, F) UCU Serina (Ser, S) UAU Tirosina (Tyr, Y) UGU Cisteína (Cys, C) U
UUC
Fenilalanina UCC Serina UAC Tirosina UGC Cisteína
C
UUA
Leucina (Leu, L) UCA Serina UAA Alto UGA Alto
A
UUG
Leucina UCG Serina UAG Alto UGG Triptófano (Trp, W)
G
C
CUU Leucina CCU Prolina (Pro, P) CAU Histidina (His, H) CGU Arginina (Arg, R)
U
CUC
Leucina CCC Prolina CAC Histidina CGC Arginina
C
CUA
Leucina CCA Prolina CAA Glutamina (Gln, Q) CGA Arginina
A
CUG
Leucina
CCG Prolina CAG Glutamina CGG Arginina
G
A
AUU Isoleucina (Ile, l) ACU Treonina (Thr, T) AAU Aspargina (Asp, D) AGU Serina (Ser, S)
U
AUC
Isoleucina ACC Treonina AAC Aspargina AGC Serina
C
AUA
Isoleucina
ACA Treonina AAA Lisina (Lys, K) AGA Arginina (Arg, R)
A
AUG
Metionina (Met, M) Inicio ACG Treonina AAG Lisina AGG Arginina
G
G
GUU Valina (Val, V) GCU Alanina (Ala, A) GAU Ácido aspártico (Asp, D) GGU Glicina (Gly, G)
U
GUC
Valina GCC Alanina GAC Ácido aspártico GGC Glicina
C
GUA
Valina
GCA Alanina GAA Ácido glutámico (Glu, E) GGA Glicina
A
GUG Valina GCG Alanina GAG Ácido glutámico GGG Glicina G
224 UNIDAD 2 Herencia
$51
KHEUDPROGHGH$'1
GLUHFFLʼnQGH
ODWUDQVFULSFLʼnQ
SURPRWRU
FRPLHQ]RGHO
JHQH[WUHPRÿ
VHŅDOGHWHUPLQDFLʼnQ
JHQ
JHQ
JHQ
;LYTPUHJP}U!DOILQDOGHOJHQOD$51SROLPHUDVDHQFXHQWUDXQDVHFXHQFLDGH$'1
OODPDGDVHŅDOGHWHUPLQDFLʼnQ/D$51SROLPHUDVDVHGHVSUHQGHGHO$'1\OLEHUDODPROÒFXOD
GH$51
,SVUNHJP}U!OD$51SROLPHUDVDUHFRUUHODKHEUDPROGHGH$'1D]XOGHVHQUROODODGREOH
KÒOLFHGH$'1\VLQWHWL]D$51FDWDOL]DQGRODDGLFLʼnQGHQXFOHʼnWLGRVGHULERVDDXQDPROÒFXOD
GH$51URMR/RVQXFOHʼnWLGRVGHO$51VRQFRPSOHPHQWDULRVGHODKHEUDPROGHGHO$'1
0UPJPHJP}U!OD$51SROLPHUDVDVHHQOD]DDODUHJLʼnQGHOSURPRWRUGHO$'1FHUFDGHOLQLFLR
GHXQJHQ\VHSDUDODGREOHKÒOLFHFHUFDGHOSURPRWRU
*VUJS\ZP}UKLSH[YHUZJYPWJP}U!GHVSXÒVGHODWHUPLQDFLʼnQHO$'1VHHQUROOD
FRPSOHWDPHQWHHQIRUPDGHGREOHKÒOLFH/DPROÒFXODGH$51TXHGDOLEUH\SDVDGHOQŜFOHR
DOFLWRSODVPDSDUDODWUDGXFFLʼnQ\OD$51SROLPHUDVDSXHGHLUDRWURJHQSDUDYROYHUDLQLFLDU
ODWUDQVFULSFLʼnQ
$'1
$'1
$51
$51
SROLPHUDVD
$'1
FIGURA 12-3 La transcripción es
la síntesis de ARN a partir de las
instrucciones del ADN Un gen es un
segmento del ADN de un cromosoma. Una
de las hebras de ADN se utiliza de molde
para la síntesis de la molécula de ARN con
bases complementarias de las bases en la
hebra de ADN.
PREGUNTA Si la otra hebra de ADN de
esta molécula fuera una hebra molde,
¿en qué dirección se movería la ARN
polimerasa?
Cuando la ARN polimerasa se une con la región del pro-
motor de un gen, la doble hélice del ADN al comienzo del gen se
desenrolla y comienza la transcripción (
FIGURA 12-3 ❶).
La elongación produce una cadena
de ARN alargada
La ARN polimerasa recorre una de las hebras del ADN, la hebra
molde, y sintetiza una hebra única de ARN con bases complemen-
tarias de la hebra del ADN (
FIGURA 12-3 ❷). Al igual que la ADN
polimerasa (véase la página 211), la ARN polimerasa siempre reco-
rre la hebra molde del ADN empezando por el extremo 3 de un
gen hacia el extremo 5. El emparejamiento de bases entre el ARN
y el ADN es el mismo que entre dos hebras de ADN, salvo porque
el uracilo el ARN se empareja con la adenina del ADN (véase la
Tabla 12-1).
Tras agregar unos 10 nucleótidos a la cadena de ARN en cre-
cimiento, los primeros nucleótidos de la molécula de ARN se
separan de la hebra molde del ADN. Esta separación permite a las

Expresión y regulación de los genes Capítulo 12 225
dos hebras enrollarse en la forma de una doble hélice (FIGURA
12-3
❸). Conforme la transcripción sigue alargando la molécula
del ARN, un extremo de ésta deriva del ADN, mientras que la
ARN polimerasa mantiene el otro extremo unido a la hebra mol-
de del ADN (figura 12-3 ❸ y
FIGURA 12-4).
La transcripción se detiene cuando la ARN
polimerasa llega a la señal de terminación
La ARN polimerasa continúa por la hebra molde del gen hasta que
llega a una secuencia de bases de ADN conocida como señal de
terminación. En este punto, la ARN polimerasa suelta la molécula
completa de ARN y se despega del ADN (
FIGURA 12-3 ❸ y ❹). La
ARN polimerasa queda libre para unirse a la región del promotor
de otro gen y sintetizar otra molécula de ARN.
12.3
¿CÓMO SE TRANSCRIBE LA SECUENCIA
DE BASES DEL ARN MENSAJERO EN
PROTEÍNAS?
La síntesis del ARN mensajero difiere entre
procariontes y eucariontes
El primer paso para sintetizar una proteína es producir una mo-
lécula de ARN mensajero con la secuencia de bases especificada
por el gen que codifica la secuencia de aminoácidos de la proteína.
Las células procariontes y eucariontes varían considerablemente en
cuanto a cómo producen una molécula funcional de ARNm a par-
tir de las instrucciones de su ADN.
Síntesis del ARN mensajero en procariontes
Los genes procariontes son por lo regular compactos. Todos los
nucleótidos de un gen codifican los aminoácidos de una proteína.
Más aún, casi todos los genes de una vía metabólica se asientan
extremo con extremo en el cromosoma (
FIGURA 12-5a). Por tanto,
las células procariontes transcriben frecuentemente un ARNm úni-
co y muy largo a partir de una serie de genes contiguos. Como las
células procariontes no tienen una membrana nuclear que separe
su ADN del citoplasma (véase la figura 4-19), la transcripción y
la traducción no están separadas ni en el espacio ni en el tiempo.
En la mayor parte de los casos, cuando una molécula de ARNm
comienza a separarse del ADN durante la transcripción, los ribo-
somas comienzan de inmediato a traducir el ARNm en proteínas
(
FIGURA 12-5b).
PROÒFXODV
GH$51HQ
FUHFLPLHQWR
ILQGHO
JHQ
LQLFLR
GHOJHQ
JHQ
$'1
G
L
U
H
F
F
L
ʼn
Q
G
H
O
D
W
U
D
Q
V
F
U
L
S
F
L
ʼn
Q
PROÒFXODV
GH$51HQ
FUHFLPLHQWR
ILQGHO
JHQ
LQLFLR
GHOJHQ
JHQ
$'1
G
L
U
H
F
F
L
ʼn
Q
G
H
O
D
W
U
D
Q
V
F
U
L
S
F
L
ʼn
Q
FIGURA 12-4 La transcripción del ARN en acción En esta
micrografía electrónica se muestra el avance de la transcripción del
ARN en el óvulo de una rana con garras africana. En cada estructura
arboriforme, el “tronco” del centro es el ADN y las “ramas” son
moléculas de ARN. Una serie de moléculas de ARN polimerasa (muy
pequeñas para ser vistas en esta micrografía) recorren el ADN y
sintetizan ARN al pasar. El comienzo del gen está a la izquierda. Las
moléculas cortas de ARN de la izquierda han comenzado a formarse;
las moléculas grandes de ARN de la derecha están casi terminadas.
PREGUNTA ¿Por qué crees que se sintetizan tantas moléculas en
el mismo gen?
H6YNHUPaHJP}UKLSVZNLULZLU\UJYVTVZVTHWYVJHYPVU[L
ULERVRPD
SURWHķQD
$51P
$'1
$51P
ULERVRPD
$51
SROLPHUDVD
GLUHFFLʼnQGHWUDQVFULSFLʼnQ
JHQHVTXHFRGLILFDQHQ]LPDV
HQXQDŜQLFDYķDPHWDEʼnOLFD
JHQ
JHQTXHUHJXODODV
VHFXHQFLDVGH$'1
JHQ JHQ
I;YHUZJYPWJP}U`[YHK\JJP}UZPT\S[mULHZLUWYVJHYPVU[LZ
$'1
FIGURA 12-5 Síntesis del ARN mensajero en las células
procariontes (a) En las células procariontes, muchos genes o todos
los de una vía metabólica completa se encuentran lado a lado en el
cromosoma. (b) La transcripción y traducción son simultáneas en las
procariontes. En la micrografía electrónica, la ARN polimerasa (que
no se distingue con este aumento) se mueve de izquierda a derecha
en una hebra de ADN. Al tiempo que sintetiza una molécula de ARN
mensajero, los ribosomas se unen al ARNm y comienzan de inmediato
a sintetizar una proteína (no visible). El diagrama que está abajo de la
micrografía muestra las principales moléculas involucradas.
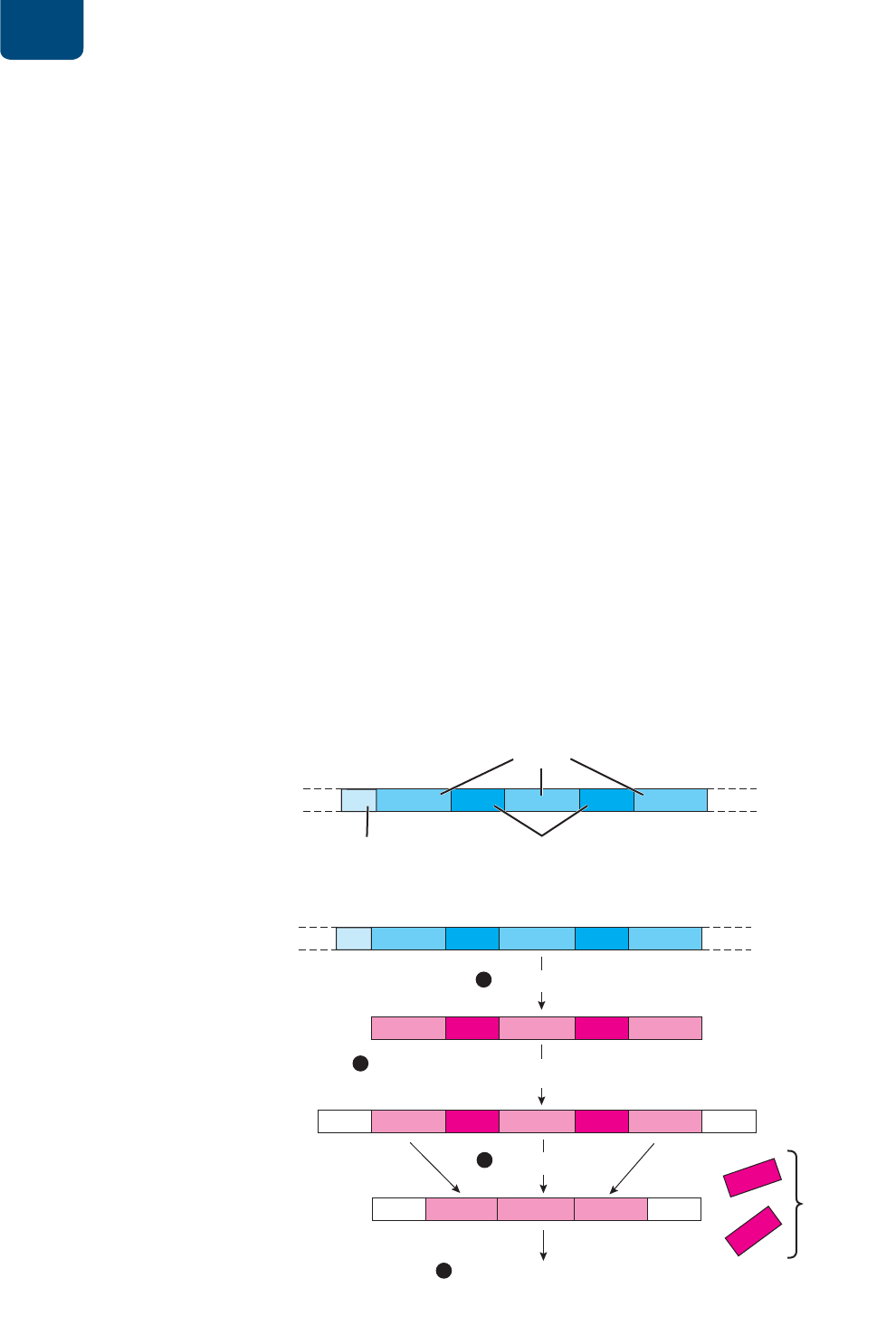
226 UNIDAD 2 Herencia
Síntesis del ARN mensajero en eucariontes
En contraste, el ADN de los eucariontes está contenido en el nú-
cleo, mientras que los ribosomas residen en el citoplasma. Asimis-
mo, los genes que codifican las proteínas necesarias para una vía
metabólica en los eucariontes no se agrupan como en los proca-
riontes, sino que pueden estar dispersos en varios cromosomas.
Por último, cada gen eucarionte consta de dos o más segmentos
de ADN con secuencias de nucleótidos que codifican una proteína,
interrumpidas por otras secuencias de nucleótidos que no se tradu-
cen en proteínas. Los segmentos de codificación se llaman exones,
porque se expresan en proteínas y los segmentos no codificadores
se llaman intrones, porque son “intragénicos”, es decir, están den-
tro de los genes (
FIGURA 12-6a). ¡Casi todos los genes eucariontes
tienen intrones; los genes de distrofinas (véanse las páginas 194-
195) contienen casi 80!
La transcripción de un gen eucarionte produce una hebra
muy larga de ADN llamada ARNm precursor o preARNm, que
comienza antes del primer exón y termina después del último
(
FIGURA 12-6b ❶). Más nucleótidos se suman al comienzo y al
final de estas moléculas de preARNm y forman un “tope” y una
“cola” (
FIGURA 12-6b ❷). Estos nucleótidos ayudan a trasladar
el ARNm terminado por la envoltura nuclear al citoplasma, para
que se enlace con el ARNm de un ribosoma y para evitar que
las enzimas celulares degraden la molécula. Para convertir esta
molécula preARNm en el ARNm maduro, las enzimas del núcleo
cortan el preARNm en las uniones entre intrones y exones, aco-
plan los exones que codifican proteínas y descartan los intrones
(
FIGURA 12-6b ❸). Las moléculas de ARNm maduro dejan el nú-
cleo y entran en el citoplasma a través de los poros de la envoltura
nuclear (
FIGURA 12-6b ❹). En el citoplasma, el ARNm se une
a los ribosomas, que sintetizan una proteína especificada por la
secuencia de bases del ARNm.
Posibles funciones de la estructura
de intrones y exones de los genes
¿Por qué los genes eucariontes contienen intrones y exones? Esta
estructura de los genes parece cumplir por lo menos dos funciones.
La primera función es permitir que la célula produzca numerosas
proteínas a partir de un gen único, acoplando los exones de dife-
rentes maneras. Por ejemplo, un gen llamado CT/CGRP se trans-
cribe en la tiroides y en el cerebro. En la tiroides, una forma de
división da por resultado la síntesis de la hormona calcitonina,
que regula las concentraciones de calcio en la sangre. En el cerebro,
otra forma de división estimula la síntesis de una proteína que sir-
ve como mensajera para la comunicación entre células nerviosas.
Otras divisiones pueden ocurrir en el ARN transcrito a partir de
más de la mitad de los genes eucariontes. Por tanto, en las euca-
riontes, la regla “un gen, una proteína” debe corregirse como “un
gen, una o más proteínas”.
La segunda función de los genes interrumpidos es más es-
peculativa, pero se sostiene en buenas evidencias experimentales.
Los genes fragmentados pueden proporcionar a los eucariontes
una manera rápida y eficaz de evolucionar nuevas proteínas con
nuevas funciones. A veces los cromosomas se separan y sus partes
se unen a diferentes cromosomas. Si la ruptura ocurre en los intro-
nes no codificadores de un gen, es posible que los exones pasen
intactos de un cromosoma a otro. Casi todos esos errores serían
dañinos, pero en ocasiones, el intercambio accidental de exones
entre genes produce nuevos genes eucariontes que favorecen la
supervivencia y la reproducción de los organismos que los portan.
H,Z[Y\J[\YHKLSNLUL\JHYPVU[L
$'1
SURPRWRU
H[RQHV
LQWURQHV
I:xU[LZPZ`WYVJLZHTPLU[VKLS(95LUL\JHYPVU[LZ
$'1
7UDQVFULSFLʼnQ
$51PPDGXUR
SUH$51P
6HDJUHJDQXQWRSHXQDFROD\XQDVHFXHQFLDGH
QXFOHʼnWLGRVGHDGHQLQDOODPDGDSROL$DOSUH$51P
'LYLVLʼnQGHO$51
(O$51PPDGXURVHHQYķD
DOFLWRSODVPDSDUDODWUDGXFFLʼnQ
WRSH FROD
ORVLQWURQHV
VHH[WUDHQ
\VH
GHJUDGDQ
FIGURA 12-6 Síntesis del ARNm
en células eucariontes (a) Los genes
eucariontes constan de exones (azul
medio), que codifican la secuencia de
aminoácidos de una proteína, e intrones
(azul oscuro) que no lo hacen. (b) La
síntesis del ARNm en eucariontes consta
de varias etapas:
❶ transcribir el gen
en una molécula grande de preARNm;
❷ agregar un nucleótido modificado al
preARNm para formar el tope y la cola
en el extremo 5 y una secuencia de
nucleótidos de adenina para formar la
cola de poli-A en el extremo 3;
❸ cortar
los intrones y acoplar los exones en el
ARNm maduro, y ❹ el ARNm maduro
sale del núcleo al citoplasma para la
traducción.

Expresión y regulación de los genes Capítulo 12 227
En la traducción, el ARNm, el ARNt y los ribosomas
cooperan para sintetizar proteínas
Vamos a describir la traducción únicamente en las células euca-
riontes (
FIGURA 12-7), pero las diferencias entre eucariontes y
procariontes son cruciales para la acción de muchos antibióti-
cos comunes para tratar infecciones bacterianas (véase la sección
“Guardián de la salud: Genética, evolución y medicina”).
Como la transcripción, la traducción tiene tres etapas: (1) ini-
ciación, (2) elongación de la cadena proteínica y (3) terminación.
Iniciación: la traducción comienza cuando el ARNt
y el ARNm se unen a un ribosoma
Un complejo de preiniciación —compuesto por la subunidad me-
nor del ribosoma, un ARNt (de inicio) que lleva metionina y otras
proteínas (
FIGURA 12-7 ❶)— se enlaza al comienzo de una molé-
cula de ARNm. El complejo de preiniciación barre el ARNm hasta
que encuentra un codón de inicio (AUG), que forma pares de bases
con el anticodón UAC de la metionina (
FIGURA 12-7 ❷). A con-
tinuación, la subunidad mayor del ribosoma se une a la subuni-
dad menor de modo que oprimen en medio al ARNm y sostienen
al ARNt con la metionina en su primer sitio de enlace del ARNt
(
FIGURA 12-7 ❸). Así, el ribosoma está completamente armado y
listo para comenzar la traducción.
Elongación: se agregan aminoácidos uno por uno
a la cadena proteínica en crecimiento
Un ribosoma mantiene alineados dos codones de ARNm con los
dos sitios de enlace del ARNt de la subunidad mayor. Un segundo
ARNt, con un anticodón complementario del segundo codón
del ARNm, pasa al segundo sitio de enlace de la subunidad mayor
(
FIGURA 12-7 ❹). El sitio de catálisis de la subunidad mayor rom-
pe el enlace que sostiene al primer aminoácido (metionina) a su
ARNt y forma un enlace peptídico entre este aminoácido y el ami-
noácido unido al segundo ARNt (
FIGURA 12-7 ❺). Es interesante
observar que el ARN ribosómico, y no una de las proteínas de la
subunidad mayor, cataliza la formación del enlace peptídico; por
tanto, este ARN enzimático se llama también “ribozima”.
Guardián de la salud
Genética, evolución y medicina
Toda la vida en la Tierra está emparentada por la evolución,
unas veces con un parentesco cercano (perros y zorros) y otras
distante (bacterias y personas). Aunque los genes suelen ser
parecidos, los genes de organismos muy distantes pueden
variar en muchas bases. La medicina aprovecha estas diferencias
para desarrollar antibióticos para infecciones bacterianas.
La estreptomicina y la neomicina son dos antibióticos que
se recetan comúnmente, éstos se enlazan a una secuencia
específica de ARN en subunidades menores de los ribosomas de
ciertas bacterias, con lo que inhiben la síntesis de las proteínas.
Sin una adecuada síntesis de las proteínas, las bacterias mueren,
pero los pacientes infectados con estas bacterias no fallecen,
porque las subunidades menores de los ribosomas eucariontes
de los seres humanos tienen otra secuencia de bases que los
ribosomas procariontes de las bacterias.
Es probable que hayas oído hablar de la resistencia a
los antibióticos, por la cual las bacterias que se exponen
frecuentemente a estos compuestos adquieren defensas. Las
bacterias evolucionan rápidamente y se vuelven resistentes a
la neomicina y a otros antibióticos afines. ¿Cómo? Bueno, si los
ribosomas eucariontes son insensibles a la neomicina, entonces
deben funcionar perfectamente bien con otra secuencia de
ARN que los ribosomas procariontes. Las bacterias que son
resistentes a la neomicina y sus afines tienen una mutación
que cambia una única base de su ARN ribosómico de adenina
a guanina, que es precisamente la base que se encuentra en el
lugar equivalente del ARN ribosómico eucarionte.
Como se ilustra con este ejemplo, la genética, las
mutaciones, los mecanismos de la síntesis de proteínas
y la evolución son importantes no sólo para los biólogos,
sino también para los médicos. De hecho, ha surgido una
disciplina llamada medicina evolutiva que considera las
relaciones evolutivas entre personas y microbios para
combatir las enfermedades.
Estudio de caso continuación
Fibrosis quística
Recuerda que en el capítulo 4 se vio que las proteínas
incrustadas en la membrana plasmática son sintetizadas por
ribosomas del retículo endoplasmático rugoso, al cual penetran
para ser procesadas. El alelo defectuoso más común que
causa la fibrosis quística produce una proteína CFTR de forma
errónea que se degrada dentro del retículo endoplasmático.
Otros cuatro alelos mutantes codifican un codón terminal en la
mitad de la proteína, así que la traducción se acaba a medias.
Estos alelos producen una falta total de la proteína CFTR y, por
consiguiente, causan fibrosis quística muy grave.
Después de formarse el enlace peptídico, el primer ARNt
queda “vacío” y el segundo lleva una cadena de dos aminoácidos.
A continuación, el ribosoma libera el ARNt vacío y pasa al siguien-
te codón de la molécula de ARNm (
FIGURA 12-7 ❻). El ARNt que
sostiene la cadena alargada de aminoácidos también se desplaza
y pasa del segundo al primer sitio de enlace del ribosoma. Un
nuevo ARNt, con un anticodón complementario del tercer codón
del ARNm, se une con el segundo sitio vacío (
FIGURA 12-7 ❼). El
sitio de catálisis de la subunidad mayor enlaza el tercer aminoáci-
do a la cadena proteínica que sigue creciendo (
FIGURA 12-7 ❽).
El ARNt vacío deja el ribosoma, éste se desplaza al siguiente codón
del ARNm y se repite el proceso, un codón cada vez.
Terminación: un codón de término
señala el fin de la traducción
Un codón de término de la molécula de ARNm señala al ribosoma
el final de la síntesis de la proteína. Los codones de término no se
unen al ARNt, sino que se unen al ribosoma unas proteínas llama-
das “factores de liberación” cuando topa con un codón de término,
lo que obliga al ribosoma a soltar la cadena proteínica terminada y
el ARNm (
FIGURA 12-7 ❾). El ribosoma se desarma en sus subu-
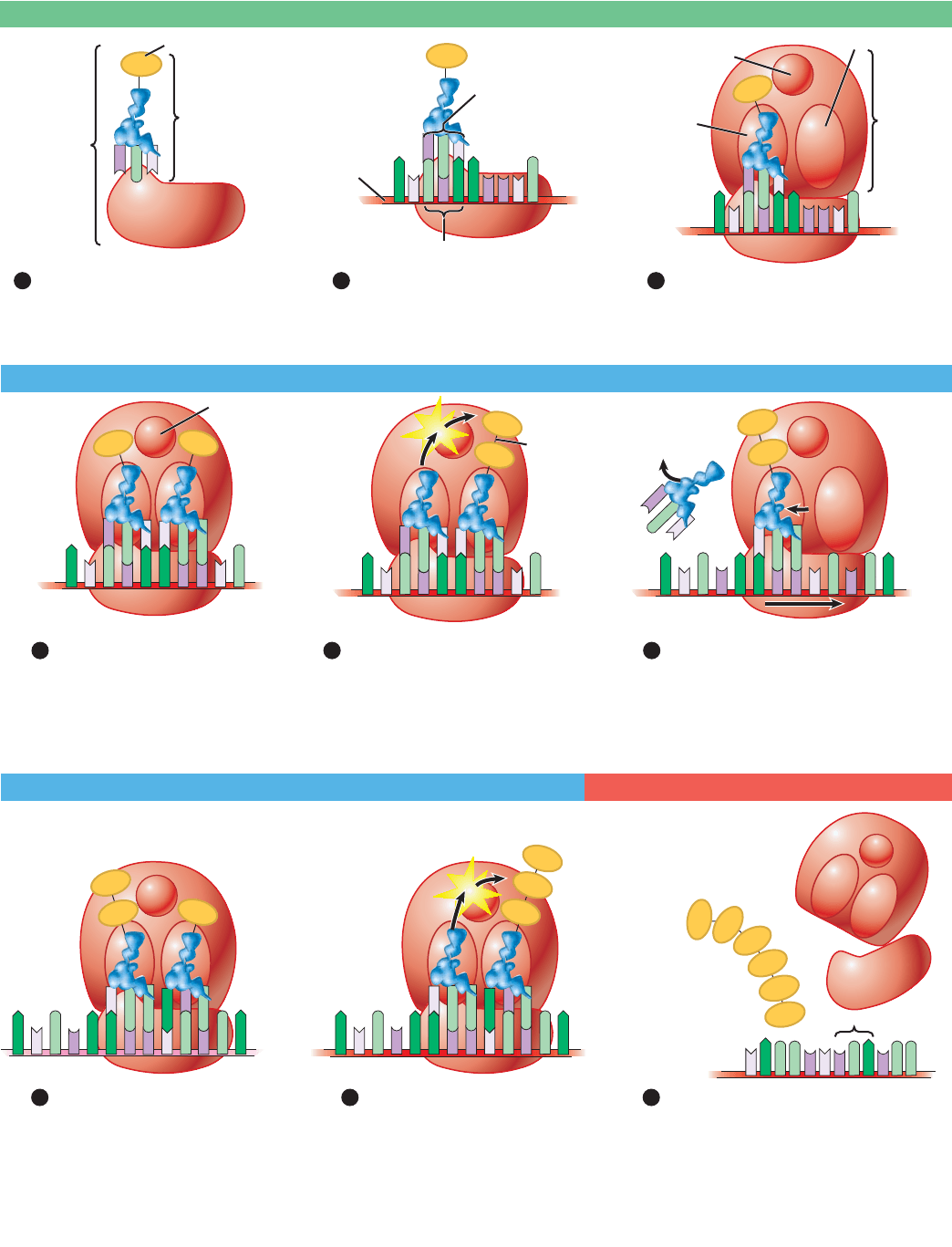
G
subunidad
menor del
ribosoma
ARNt
anticodón
ARNt con
metionina
aminoácido
primer
sitio de
enlace
del ARNt
sitio catalítico
segundo sitio de enlace del ARNt
Iniciación:
complejo de
preiniciación
met
met
met
Un ARNt con un aminoácido
metionina se une a una subunidad
menor del ribosoma y forma un
complejo de preiniciación.
La subunidad mayor del ribosoma se
enlaza con la subunidad menor. El ARNt que
lleva el aminoácido metionina se une con el
primer sitio del ARNt de la subunidad mayor.
El complejo de preiniciación se une
a una molécula de ARNm. El anticodón
ARNt (UAC) que lleva el aminoácido
metionina se empareja con el codón de
inicio (AUG) del ARNm.
C
AA
C
CGGGU
U
U
A
A
ACCGGGUUU
C
A
U
C
A
U
ARNm
subunidad
mayor del
ribosoma
U
sitio
catalítico
enlace
peptídico
el ribosoma se mueve un codón a la derecha
Elongación:
Terminación:
met
met
val
met
val
val
El ARNt “vacío” queda libre y el ribosoma
avanza por el ARNm, un codón a la derecha.
El ARNt que se une a los dos aminoácidos
está ahora en el primer sitio de enlace del
ARNt y el segundo sitio de enlace de ARNt
está vacío.
El sitio catalítico de la subunidad
mayor cataliza la formación de un
enlace peptídico que une los
aminoácidos metionina y valina. Los
dos aminoácidos quedan unidos al
ARNt en el segundo sitio de enlace.
El segundo codón del ARNm
(GUU) se empareja con el
anticodón (CAA) del segundo ARNt
que lleva el aminoácido valina (val).
Este ARNt se enlaza a un segundo
sitio de ARNt en la subunidad
mayor.
AU
AACCGGGUUU
AACCGGGGUUU
C
AA
AA
C
A
U
C
A
U
AACCGGGUUU
CAACAU
Se libera el
ARNt iniciador
C
his
met
val
arg
arg
ile
codón de término
met
val
his
El sitio catalítico forma un
enlace peptídico entre la valina y
la histidina, y deja el péptido
unido al ARNt del segundo sitio
de enlace. El ARNt del primer sitio
se libera y el ribosoma se mueve
un codón en el ARNm.
El proceso se repite hasta dar
con un codón de término. El
ARNm y el péptido completo se
liberan del ribosoma y las
subunidades se separan.
AA A AACCGGUUU
AU
AA
A
CCGG
G
GUU
U
U
CAA
péptido
completo
his
met
val
El tercer codón del ARNm
(CAU) se empareja con el
anticodón (GUA) de un ARNt que
lleva el aminoácido histidina
(his). Este ARNt entra en el
segundo sitio de enlace del
ARNt en la subunidad mayor.
AU
AA
A
CCGG G
G
GUU
U
U
CAA
codón de inicio
1
4
789
23
56
FIGURA 12-7 La traducción es la síntesis de proteínas La traducción descifra la secuencia de bases de un ARNm en la forma de la
secuencia de aminoácidos de una proteína.
PREGUNTA Examina el paso ➒. Si las mutaciones cambiaran todas las moléculas de guanina visibles en la secuencia de ARNm por uracilo,
¿cuál sería la variación en el péptido traducido del que se representa en la figura?
Expresión y regulación de los genes Capítulo 12 229
nidades mayor y menor, que pueden volver a usarse para traducir
otro ARNm.
Protein Synthesis (disponible en inglés)
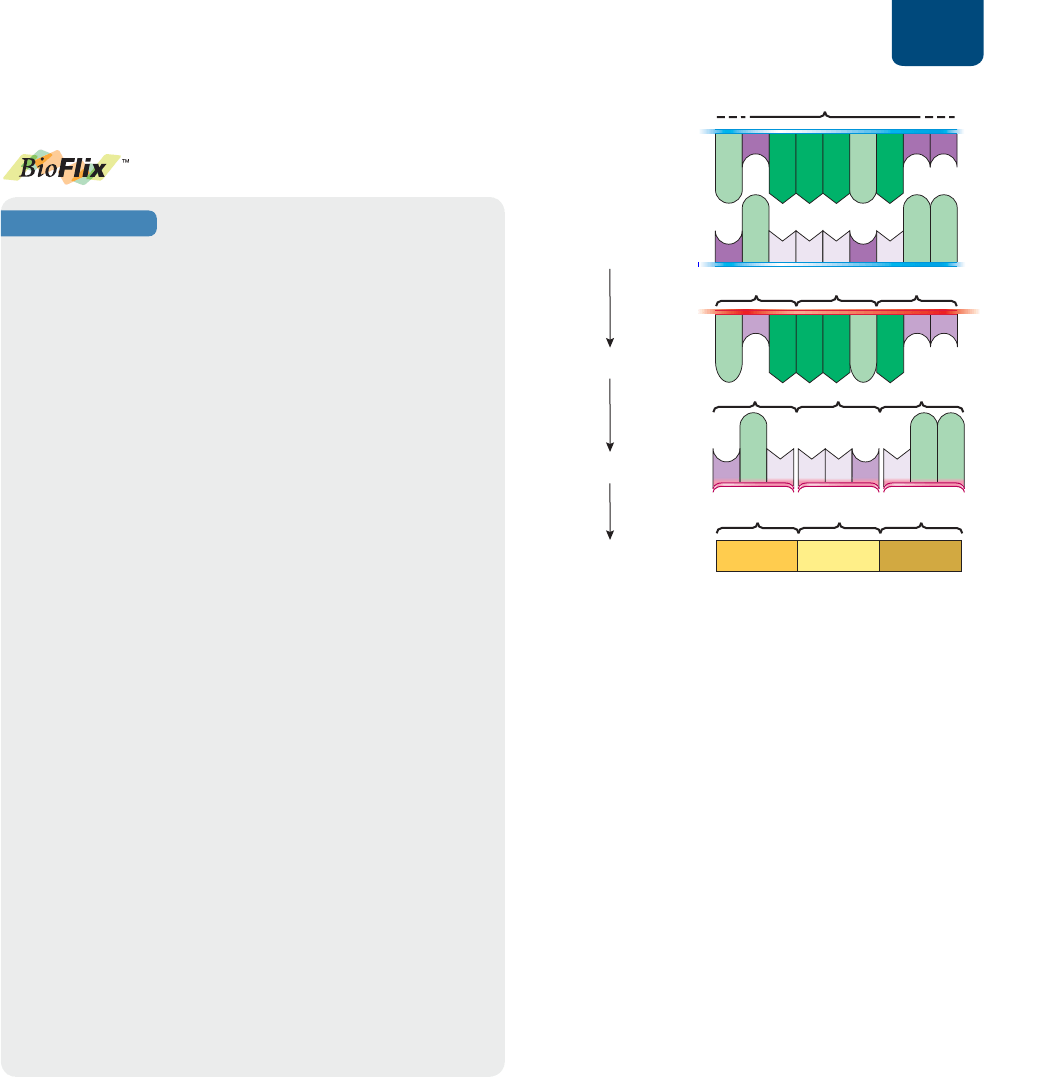
En resumen
Descifrar la secuencia de bases del
ADN en la secuencia de aminoácidos de una proteína
requiere transcripción y traducción
Vamos a resumir cómo las células eucariontes decodifi-
can la información genética guardada en su ADN para
sintetizar una proteína (
FIGURA 12-8).
a. Con algunas excepciones, como con los genes del
ARNt y del ARNr, cada gen codifica la secuencia de
aminoácidos de una proteína. El gen del ADN cons-
ta de la hebra molde, que se transcribe en ARNm, y
de su hebra complementaria, que no se transcribe.
b. La transcripción de un gen que codifica una proteína
produce una molécula de ARNm que es complemen-
taria de la hebra molde del gen del ADN. A partir del
primer AUG, cada codón del ARNm es una secuencia
de tres bases que especifica un aminoácido o un “alto”.
c. Las enzimas del citoplasma se unen al aminoácido
apropiado de cada ARNt basándose en el anticodón
de este ARNt.
d. El ARNm sale del núcleo y se une a un ribosoma
del citoplasma. Los ARN de transferencia llevan sus
aminoácidos unidos al ribosoma. Ahí, las bases de los
anticodones del ARN se unen a sus bases complemen-
tarias en los codones del ARNm, así que los aminoá-
cidos unidos a los ARNt se alinean en la secuencia
especificada por los codones. El ribosoma se une a los
aminoácidos con enlaces peptídicos para formar una
proteína. Cuando se llega a un codón de término,
la proteína terminada se libera del ribosoma.
Esta cadena de decodificación, desde las bases de
ADN a los codones del ARNm, a los anticodones del
ARNt y finalmente a los aminoácidos, da por resultado la
síntesis de una proteína con una secuencia de aminoáci-
dos determinada por la secuencia de bases de un gen.
Inversiones y translocaciones
Las inversiones y las translocaciones ocurren cuando segmentos
del ADN (a veces casi todo o todo un cromosoma) se rompen y se
vuelven a unir, ya sea en el mismo cromosoma o en uno diferente.
Estas mutaciones pueden ser relativamente benignas si genes com-
pletos con sus promotores simplemente pasan de un lugar a otro.
Pero si un gen se divide en dos, ya no va a codificar una proteína
completa y funcional. Por ejemplo, casi la mitad de los casos de he-
mofilia grave son causados por una inversión del gen que codifica
una proteína necesaria para coagular la sangre.
Supresiones e inserciones
Los efectos de las mutaciones por supresión y las mutaciones
por inserción dependen de cómo se retiren o agreguen muchos
nucleótidos. ¿Por qué? Piensa en el código genético: tres nucleó-
tidos codifican un único aminoácido; por tanto, agregar o quitar
tres nucleótidos suma o resta un solo aminoácido de la proteína
codificada. En muchos casos, esto no altera gran cosa la función
de la proteína; en cambio, la supresión o inserción de uno o dos
nucleótidos o una supresión o inserción que no sea múltiplo de
tres nucleótidos puede tener efectos catastróficos, porque todos
los codones que siguen a la supresión o inserción quedarán al-
terados.
Recuerda nuestra frase en castellano VANLOSDOSPOR-
PAN formada con palabras de tres letras. Quitar o meter una letra
(por ejemplo, eliminar la primera A) significa que las siguientes
KHEUDPROGH
GH$'1
KHEUD
FRPSOHPHQWDULD
GH$'1
H(+5
JHQ
FRGRQHV
DQWLFRGRQHV
DPLQRÀFLGRV
HWF
HWF
HWF
HWF
I(95T
J(95[
PHWLRQLQD JOLFLQD YDOLQD
KWYV[LxUHZ
7 $&&&7 &$$
$8***$*88
8$&
&&8 &$$
HWF
$
7 *** $* 77
FIGURA 12-8 El emparejamiento de bases complementarias
es crucial al descifrar la información genética (a) El ADN de un
gen contiene dos hebras; la ARN polimerasa utiliza sólo la hebra
molde para sintetizar una molécula de ARN. (b) Las bases de la
hebra molde de ADN se transcriben a un ARNm complementario.
Los codones son secuencias de tres bases que especifican un
aminoácido o un alto durante la síntesis de proteínas. (c) Salvo que
sea un codón de término, todos los codones del ARNm forman pares
de bases con el anticodón de una molécula de ARNt que lleva un
aminoácido específico. (d) Los aminoácidos llevados por el ARNt se
unen para formar una proteína.
12.4
¿CÓMO AFECTAN LAS MUTACIONES
EL FUNCIONAMIENTO DE LAS PROTEÍNAS?
Como se vio en el capítulo 11, los errores en la replicación del
ADN, los rayos ultravioleta de la luz solar, los compuestos quími-
cos del humo del tabaco y un cúmulo de otros factores ambientales
pueden cambiar la secuencia de bases del ADN. Estos cambios se
llaman mutaciones. Las consecuencias para la estructura y fun-
ción de un organismo dependen de cómo afecte la mutación el
funcionamiento de la proteína codificada por el gen mutado.
Las mutaciones pueden tener diversos efectos
en la estructura y funcionamiento de las proteínas
Casi todas las mutaciones pueden clasificarse como sustituciones,
supresiones, inserciones, inversiones o translocaciones (véanse las
páginas 213-214).

230 UNIDAD 2 Herencia
palabras de tres letras no tendrán sentido, como VNL OSD OSP
ORP AN. De la misma manera, la mayor parte de —y posible-
mente todos— los aminoácidos de la proteína sintetizada a partir
de un ARNm que contenga esta mutación, denominada mutación
por corrimiento del marco de lectura, estarán todos equivocados.
A veces, uno de los nuevos codones después de una inserción
o supresión será un codón de término, que dejará una proteína
corta. Estas proteínas casi nunca funcionan. ¿Te acuerdas de las
reses Belgian Blue del estudio de caso del capítulo 11? El gen de-
fectuoso de miostatina de estos animales tiene una supresión en
el nucleótido 11, lo que produce un codón de término prematuro
que da por concluida la traducción antes de que se complete la
proteína miostatina.
Sustituciones
Una sustitución de nucleótidos (también llamada mutación
puntual) en un gen que codifica una proteína, produce uno de
cuatro resultados. Tomemos, por ejemplo, las mutaciones que
ocurren en el gen que codifica la betaglobina, una de las unida-
des de la hemoglobina, la proteína portadora del oxígeno en los
glóbulos rojos (
Tabla 12-4). La otra unidad de la hemoglobina es
la alfaglobina. Una molécula normal de hemoglobina tiene dos
unidades alfa y dos beta. En todos los ejemplos, salvo el último, va-
mos a considerar el resultado de las mutaciones que ocurren en el
sexto codón del gen de la betaglobina (CTC en el ADN, GAG
en el ARNm), el cual especifica el ácido glutámico, un aminoácido
cargado, hidrofílico y soluble en el agua.
• La proteína no cambia. Recuerda que varios codones dife-
rentes pueden codificar casi todos los aminoácidos. Si una
mutación cambia la secuencia de bases del ADN de la beta-
globina de CTC a CTT, esta secuencia de todos modos codifi-
ca el ácido glutámico. Por tanto, la proteína sintetizada por el
gen mutado sigue siendo la misma.
• La nueva proteína es funcionalmente equivalente a la origi-
nal. Muchas proteínas tienen regiones cuya secuencia precisa
de aminoácidos no es tan importante. En la betaglobina, los
aminoácidos del exterior de la proteína deben ser hidrofílicos
para mantener la proteína disuelta en el citoplasma de los
glóbulos rojos. Exactamente qué aminoácidos hidrofílicos se
encuentren fuera no tiene mucha importancia. Por ejemplo,
se descubrió que una familia del pueblo japonés de Machida
tiene una mutación de CTC a GTC, por la cual la glutamina
(que es hidrofílica) reemplaza al ácido glutámico (también
hidrofílico). La hemoglobina que contenga esta proteína be-
taglobina mutante (conocida como hemoglobina Machida)
funciona bien. Estas mutaciones, como la hemoglobina Ma-
chida y el ejemplo anterior, se llaman mutaciones neutras
porque no cambian notablemente la función de la proteína
detectada.
• La función de la proteína cambia por una secuencia altera-
da de aminoácidos. Una mutación de CTC a CAC cambia el
ácido glutámico (hidrofílico) por valina (hidrofóbica). Esta
sustitución es el defecto genético que causa la anemia de
células falciformes (véanse las páginas 190-191). Las valinas
del exterior de las moléculas de hemoglobina hacen que és-
tas se aglutinen, lo que distorsiona la forma de los glóbulos
rojos. Estos cambios producen una enfermedad grave.
• La función de la proteína queda anulada por un codón de
término prematuro. Ocasionalmente ocurre una mutación
catastrófica en el codón 17 del gen de la betaglobina (TTC en
el ADN, AAG en el ARNm). Este codón especifica el aminoá-
cido lisina. Una mutación de TTC a ATC (UAG en ARNm) da
por resultado un codón de término que detiene la traducción
del ARNm de la betaglobina antes de terminar la proteína.
Las personas que heredan este gen mutante de la madre y el
padre no sintetizan nada de betaglobina funcional, sino que
elaboran hemoglobina compuesta únicamente por unidades
de alfaglobina. Esta hemoglobina “alfa pura” no enlaza muy
bien el oxígeno. Se produce una condición, beta talasemia,
que puede ser mortal si no se trata con trasfusiones de sangre
periódicas durante toda la vida.
Las mutaciones producen la materia
prima de la evolución
Las mutaciones de los gametos (óvulos o espermatozoides) pue-
den transmitirse a las siguientes generaciones. En los seres hu-
manos, las tasas de mutación van de alrededor de una por 100
mil gametos a una por millón de gametos. A título de referencia,
un hombre emite de 300 a 400 millones de espermatozoides por
eyaculación. Cada emisión contiene unos 600 espermatozoides
con mutaciones nuevas. Casi todas las mutaciones son neutras o
potencialmente dañinas, pero las mutaciones son esenciales para
la evolución, porque estos cambios aleatorios de la secuencia del
Tabla 12-4 Efecto de las mutaciones en el gen de la hemoglobina
ADN (hebra
molde) ARNm Aminoácido
Propiedades de
los aminoácidos Efecto funcional en la proteína Enfermedad
Codón original 6 CTC GAG Ácido glutámico Hidrofílico Función normal de la proteína Ninguna
Mutación 1 CTT GAA Ácido glutámico Hidrofílico Neutra; función normal de la proteína Ninguna
Mutación 2 GTC CAG Glutamina Hidrofílico Neutra; función normal de la proteína Ninguna
Mutación 3 CAC GUG Valina Hidrofóbico Pérdida de la solubilidad en agua;
compromete la función de la
proteína
Anemia de células
falciformes
Codón original 17 TTC AAG Lisina Hidrofílico Función normal de la proteína Ninguna
Mutación 4 ATC UAG Codón terminal Termina la traducción
después del
aminoácido 16
Sintetiza sólo parte de la proteína;
suprime la función de la proteína
Beta talasemia
Expresión y regulación de los genes Capítulo 12 231
ADN son la fuente definitiva de toda la variación genética. Nuevas
secuencias de bases pasan por selección natural cuando los orga-
nismos compiten por sobrevivir y reproducirse. Ocasionalmente,
una mutación resulta benéfica para las relaciones del organismo
con su entorno. Al paso del tiempo, y con la reproducción, la se-
cuencia de bases mutante se transmite a toda la población, pues
los organismos que la tienen superan y se reproducen más que los
rivales que llevan la secuencia de base original. En la unidad 3 se
verá detalladamente este proceso.
12.5
¿CÓMO SE REGULAN LOS GENES?
El genoma humano completo contiene de 20 mil a 25 mil ge-
nes. Cada gen está presente en casi todas las células del cuerpo,
pero cada célula expresa (es decir, transcribe y, si el producto del
gen es una proteína, traduce) apenas una fracción. Algunos ge-
nes se expresan en todas las células porque codifican proteínas
o moléculas de ARN que son esenciales para la vida de cualquier
célula. Por ejemplo, todas las células tienen que sintetizar pro-
teínas, así que todos éstos transcriben genes de ARNt, genes de
ARNr y genes de proteínas ribosómicas. Otros genes se expresan
únicamente en ciertos tipos de células, en determinados momen-
tos de la vida de un organismo o en condiciones ambientales es-
pecíficas. Por ejemplo, aunque todas las células contienen el gen
de la caseína, una proteína importante de la leche, éste nada más
se expresa en mujeres maduras, en ciertas células de las mamas y
sólo cuando lactan.
La regulación de la expresión de un gen ocurre en el nivel
de la transcripción (qué genes se usan para hacer ARNm en una
célula), la traducción (cuánta proteína se hace a partir de un tipo
particular de ARNm) o la actividad proteínica (cuánto dura la
proteína en la célula y con qué rapidez cataliza reacciones especí-
ficas). Aunque estos principios generales se aplican a organismos
procariontes y eucariontes por igual, también hay algunas dife-
rencias, como veremos enseguida.
Regulación de los genes en los procariontes
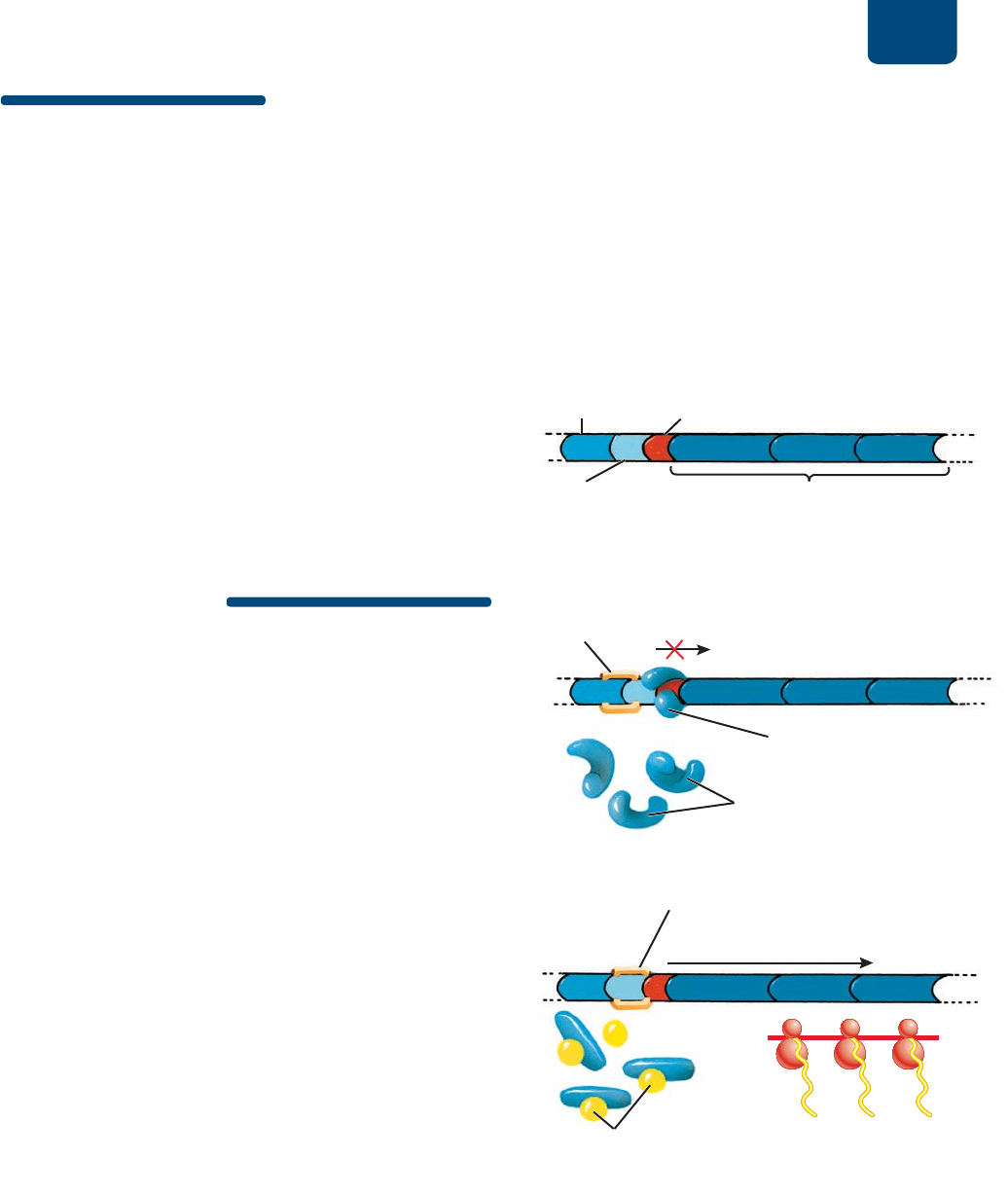
El ADN procarionte se organiza en paquetes llamados operones,
en los que los genes de funciones relacionadas se depositan unos
junto a otros (
FIGURA 12-9a). Un operón está constituido por: (1)
un gen regulador, que controla el momento o la velocidad de la
transcripción de otros genes; (2) un promotor, que la ARN polime-
rasa reconoce como el lugar donde se empieza la transcripción; (3)
Estudio de caso continuación
Fibrosis quística
¿Por qué la selección natural no ha eliminado los alelos
mutados CFTR? Quizá porque los alelos mutados confieren
protección contra el cólera y la tifoidea. La proteína CFTR
normal es activada por la toxina del cólera y produce una
secreción excesiva de cloro por las paredes celulares. El agua
la sigue por ósmosis, de modo que las víctimas del cólera
sufren una diarrea debilitante y muchas veces letal. Las
proteínas CFTR defectuosas no pueden ser activadas por la
toxina del cólera. La proteína CFTR es también el sitio por el
que la bacteria de la tifoidea penetra en la célula, pero no
puede entrar por las proteínas CFTR mutadas. Esta protección
no compensa los devastadores efectos de la fibrosis quística,
pero los heterocigotos, con un alelo CFTR normal y uno
mutado, tienen una CFTR de función casi normal y saldrían
menos afectados por el cólera y la tifoidea. Esta “ventaja de los
heterocigotos” explicaría la elevada frecuencia de alelos CFTR
mutados (alrededor de 4% de las personas de origen europeo
tienen alelos mutados CFTR), como pasa con el alelo de la
anemia de células falciformes (véase la página 190).
H,Z[Y\J[\YHKLSVWLY}USHJ[VZH
JHQUHJXODGRU
FRGLILFDODSURWHķQD
UHSUHVRUD
RSHUDGRUDTXķVHXQH
ODSURWHķQDUHSUHVRUD
SURPRWRUOD$51
SROLPHUDVDVH
HQOD]DDTXķ
JHQHVHVWUXFWXUDOHV
53
2
JHQ
JHQ
JHQ
J*VUSHJ[VZH
5
2
JHQ
JHQ
JHQ
VHVLQWHWL]DQHQ]LPDVTXH
PHWDEROL]DQODODFWRVD
ODODFWRVDVHXQHD
SURWHķQDVUHSUHVRUDV
/D$51SROLPHUDVDVHXQH
DOSURPRWRU\WUDQVFULEH
ORVJHQHVHVWUXFWXUDOHV
I:PUSHJ[VZH
5
JHQ
JHQ
JHQ
$51
SROLPHUDVD
WUDQVFULSFLʼnQEORTXHDGD
XQDSURWHķQDUHSUHVRUD
XQLGDDOVLWLRGHORSHUDGRU
VRODSDDOSURPRWRU
SURWHķQDVUHSUHVRUD
OLEUHV
3
FIGURA 12-9 Regulación del operón lactosa (a) El operón
lactosa consta de un gen regulador, un promotor, un operador y
tres genes estructurales que codifican las enzimas necesarias
para el metabolismo de la lactosa. (b) En ausencia de la lactosa,
las proteínas represoras se unen al operador del operón lactosa, la
ARN polimerasa puede enlazarse al promotor, pero no pasa de
la proteína represora para transcribir los genes estructurales.
(c) Cuando hay lactosa, se une a las proteínas represoras y las
inactiva para unirse al operador. La ARN polimerasa se une al
promotor, pasa el operador desocupado y transcribe los genes
estructurales.
Este documento contiene más páginas...
Descargar Completo
Transmision sináptica215.pdf
 Estamos procesando este archivo...
Estamos procesando este archivo...
 Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Descargar
Estamos procesando este archivo...
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.