
¿ Qué es la Estadística?
Es la ciencia de recolectar, organizar, presentar, analizar e interpretar datos para ayudar en una toma
de decisiones más efectiva (bajo condiciones de incertidumbre)
Conceptos Importantes:
*Variabilidad: Cuando efectuamos mediciones a ciertos elementos,los resultados varían de una
unidad a la otra
*Incertidumbre: Es generada cuando se trabaja con una parte de la totalidad de elementos que están
bajo consideración en una investigación
Población y Muestra
En Estadística, como las poblaciones a menudo son muy grandes, es imposible o muy costoso
recoger información de toda la población, lo que obliga a trabajar con una parte representativa de esa
población, denominada Muestra Aleatoria.
Una población es el conjunto completo de elementos o individuos que interesa en una investigación,
cada elemento se designa como unidad estadística y su tamaño se representa por la letra N. En
cambio, una muestra es una parte de la población que se selecciona para realizar una determinada
investigación y su tamaño se indica con n. Los elementos de la muestra deben ser seleccionados
aleatoriamente.
● Tanto en la población como en la muestra es muy importante determinar espacio y tiempo
● La unidad de Relevamiento es el individuo o el elemento de donde uno toma el dato o la
característica que quiere analizar, generalmente coincide con la unidad estadística pero no
necesariamente tiene que ser así,por ejemplo: en el censo de vivienda la unidad estadística
son las personas, pero la unidad de relevamiento es el hogar o el jefe de hogar que es el que
va a responder las preguntas.
Una Muestra Aleatoria es aquella en la que todos los elementos de la población tienen una
probabilidad conocida de ser seleccionados. Si la probabilidad es igual para todas las unidades
estadísticas, se trata de una Muestra Aleatoria Simple. El listado de los elementos a partir del cual
se selecciona la muestra en estadística es denominado Marco muestral. Las características de la
unidad estadística relacionada con el tema sobre el cual estamos investigando que deben relevarse y
que varían de una unidad a la otra se denominan variables en estadística.
Parámetro y Estadístico
Toda medida resumen que se calcula para describir características poblacionales se llama parámetro,
el cual es una cantidad fija que generalmente no se conoce y debe ser estimada. Es una única
medida, una constante.
Un estadístico es una medida calculada con las observaciones muestrales. Es una variable
Estadística descriptiva e inferencial
Dada la base de datos, y después de una primera organización de los datos, es posible avanzar en el
descriptivo de los datos y aplicar técnicas que permiten la resolución de problemas bajo condiciones
de incertidumbre. Teniendo en cuenta ello, podemos dividir los métodos estadísticos en dos grandes
ramas:
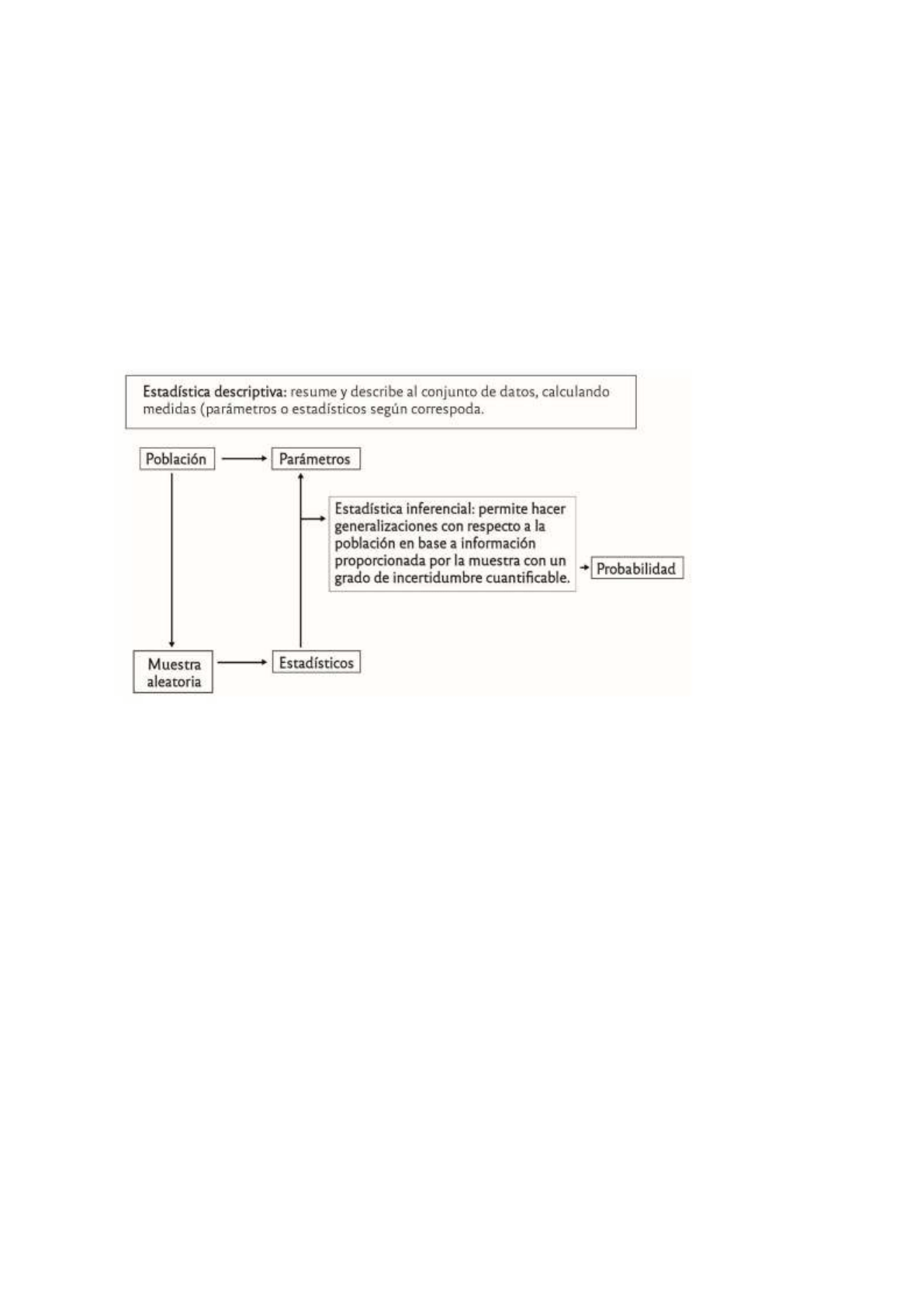
1. Estadística Descriptiva : está formada por aquellos métodos gráficos y numéricos que se
utilizan para resumir y procesar los datos, con el fin de describir sus principales
características.
2. Inferencia Estadística : incluye los métodos que permiten hacer generalizaciones con
respecto a la población con base en información proporcionada por una muestra aleatoria,
con un grado de incertidumbre cuantificable.
La Estadística Descriptiva, desde la década del 60, incorporó nuevas medidas y gráficos al análisis
descriptivo tradicional que se presentaron bajo el nombre Análisis exploratorio de datos. Los métodos
de la Estadística Inferencial se basan en la teoría de probabilidad, y permiten construir intervalos de
estimación para los parámetros desconocidos y realizar pruebas de hipótesis.
Etapas del método estadístico
Las etapas a seguir para realizar un estudio estadístico que permitirá la toma racional de decisiones,
se pueden organizar de la siguiente manera:
• Planteamiento del Problema: en primer lugar, se deben definir los objetivos del estudio, la población
objetivo, a partir de la cual se construirá el marco muestral y las variables de interés y sus relaciones.
Cuando se trabaja con una muestra, en el planteamiento del problema, se debe decidir el método de
muestreo más conveniente, determinar el tamaño de la muestra y la precisión esperada, temas que
escapan al alcance de esta materia
• Diseño y recopilación: Formulación estadística de la cuestión: definir la población de estudio a
partir del marco muestral, el tipo de estudio a realizar y las variables de interés. Diseñar cómo se
obtienen los datos, una vez recolectados se realiza un análisis de consistencia, elaborando de esta
manera la base de datos para su análisis.
• Organización y presentación de datos: se refiere a la presentación de los datos en tablas y
gráficos, que muestran su comportamiento y de este modo nos ayudan a comprender la información
recabada.
• Análisis: consiste en el cálculo de medidas descriptivas y la interpretación de la información
obtenida (estadística descriptiva), lo que, de manera conjunta, nos permitirá responder los objetivos
del estudio. Cuando se está trabajando con una muestra, los resultados se proyectan a la población,
estableciendo un error, esto forma parte de la estadística inferencial que básicamente consiste en
realizar estimaciones por intervalos, contrastar hipótesis y validar los supuestos en que se basan los
modelos planteados.
• Resultados y conclusiones: Finalmente se informan los resultados más relevantes respondiendo a
los objetivos iniciales planteados en la formulación del problema. Es importante concluir con base a
los resultados de manera adecuada, de forma tal que contribuya a una mejor comprensión y
exposición de los mismos, en función de los objetivos del trabajo
En este capítulo y en el siguiente se introducen los conceptos de las dos primeras etapas señaladas
y se ilustran las técnicas para la organización, cálculo de medidas descriptivas y su interpretación.
1. Planteamiento del Problema
Como señalamos, lo primero que se debe tener en cuenta en una investigación es definir el problema
que se quiere abordar, para lo cual debe tenerse muy en claro la población objetivo, los parámetros a
estimar y/o las pruebas de hipótesis que se plantean.
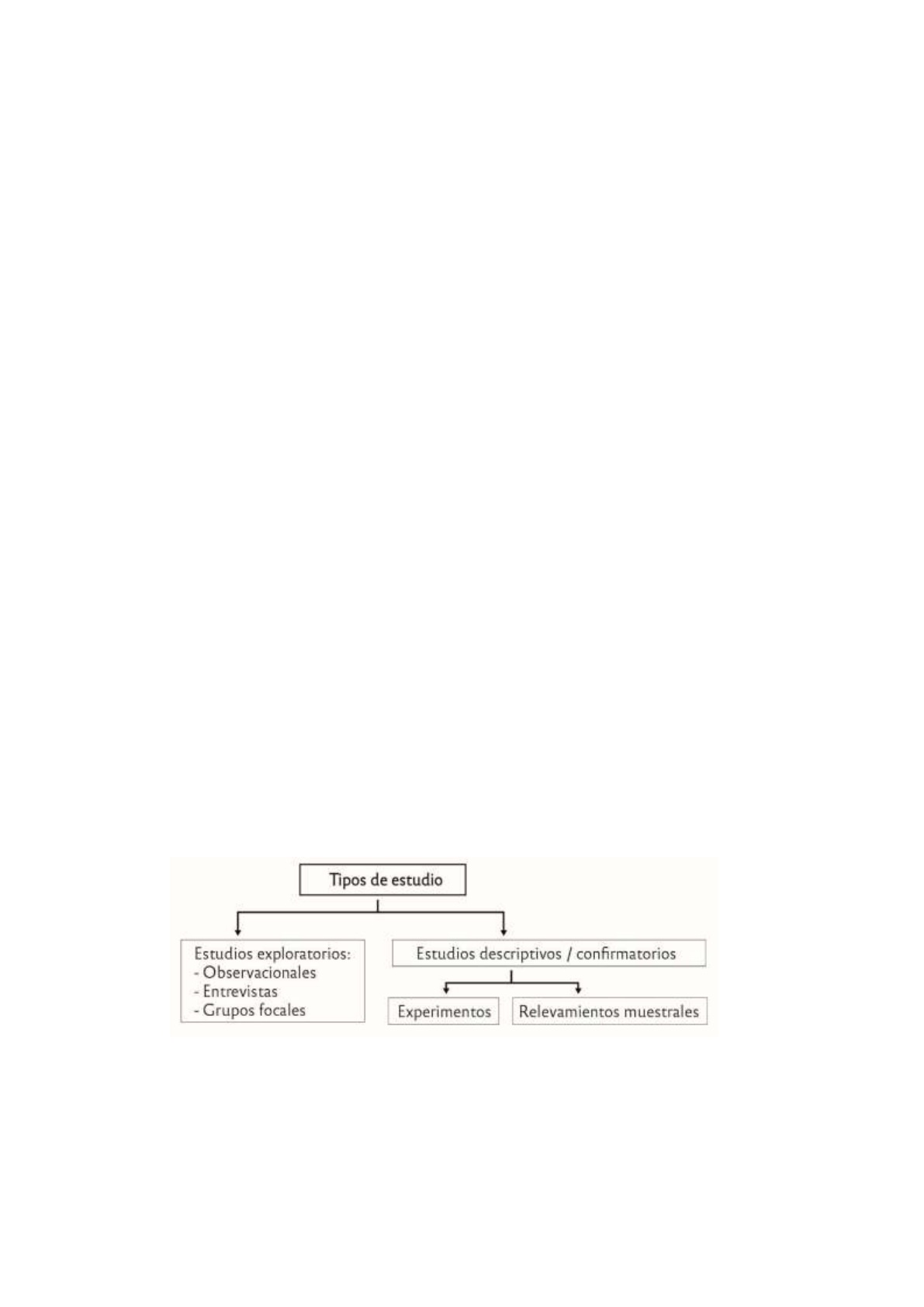
De acuerdo a los objetivos que persiguen, los estudios se clasifican como:
1. Estudios Exploratorios: -Observacionales(información de documentos) -Entrevistas
-Grupos Focales
Son indagaciones sobre cada elemento, que no son cuantificables en un número. No se
basan en selecciones aleatorias, sino que se basan en procedimientos preestablecidos. Por
este motivo, no representan al total, se eligen determinados elementos específicos. No es
información estructurada.
2. Estudios Descriptivos/ Confirmatorios: -Experimentos -Relevamientos Muestrales
En estos estudios el objetivo es hacer inferencia respecto a la población, para lo que se
trabaja con una muestra aleatoria. En los relevamientos muestrales se estiman parámetros
desconocidos de la población. En los experimentos el diseño es más exigente ya que se
quieren probar relaciones de causalidad.
Generan resultados estructurados y cuantificables, para obtener resultados numéricos.
2. Recopilación de datos
Los datos pueden provenir de fuentes primarias o secundarias.
Una de las principales fuentes primarias es la encuesta por muestreo (“survey”), en los que los datos
son recolectados aplicando un cuestionario a los elementos de la población o muestra seleccionada.

Los datos de fuentes secundarias son aquellos que han sido reunidos y publicados por otras
instituciones. En general se trabaja con datos provenientes de organismos públicos o privados tales
como INDEC, BCRA, AFIP, Cámaras empresariales, ONU, FMI, sólo para mencionar algunos
5.3. Tipos de variables
En estadística, cada una de las características a estudiar se denomina variable, la cual admite
diversas respuestas para las unidades estadísticas. A su vez, la realización de una respuesta
particular constituye un dato.
Clasificación de las variables
Las variables se clasifican en:
Cuando la pregunta admite como respuesta un número, se trata de una variable cuantitativa o
numérica.
A su vez, si los valores que asume la variable surgen de un conteo o de una enumeración, la variable
es numérica discreta, como por ejemplo “cantidad de materias aprobadas” (números enteros). En
cambio, si se obtienen datos a través de un sistema de medición, la variable es continua ya que
asumiría valores en un intervalo (números reales). En el relevamiento a los alumnos, el “gasto en
libros” y la “estatura” constituyen ejemplos de este tipo de variables. Otro ejemplo son las variables en
unidad de tiempo y monetarias, como la edad o el salario.
Cuando la variable no admite una respuesta numérica, sino que la unidad de análisis se asigna a una
clase o categoría la variable es cualitativa o categórica. Ejemplos de variables cualitativas son: sexo,
lugar de procedencia, nivel de educación de los padres, el motivo por el cual necesita financiación
para exportar.
¿Cómo se miden las variables?
La medición de una variable es el proceso de asignar números o símbolos a los elementos. La regla
por la cual se asignan los números o símbolos constituye una escala de medición, y cada escala
cuenta con propiedades que la distinguen.
La escala de medición es nominal cuando los elementos se asignan a categorías preestablecidas.
La propiedad que la caracteriza es categorizar o dar categorías. A estas categorías se le suelen
asignar números.
Las categorías a las que se le asignan las unidades de observación son mutuamente excluyentes y
exhaustivas. Mutuamente excluyente ya que si un elemento pertenece a una categoría, no puede

pertenecer a la otra. Exhaustivas ya que todos los elementos de la población o muestra deben ser
clasificados en una categoría.
En el caso particular en el que las variables presentan sólo dos categorías se las llama variables
dicotómicas.
La escala es ordinal cuando las respuestas están dispuestas en un cierto orden. Al asignar números
se utiliza la propiedad de orden, como por ejemplo la variable “nivel de educación de los padres”.
También aquí las categorías deben ser mutuamente excluyentes y exhaustivas.
Las escalas de intervalo y de razón que veremos a continuación sólo pueden utilizarse con
variables numéricas.
La escala de intervalo agrega a la propiedad de orden la propiedad de igualdad de diferencias,dada
por distancias o intervalos iguales. No solo permite conocer cuál es el valor más grande, sino
cuantificar en cuanto es más grande. En esta clase de medida, la proporción entre dos intervalos
cualesquiera es independiente de la unidad de medida y del punto cero.
Sin embargo, en la mayoría de las mediciones con escala numérica, se define un punto cero real en
su origen, lo que define una escala de razón. Son variables donde el cero indica la nulidad o la
ausencia de lo que se estudia. En esta escala, además de la distinción de orden y distancia , permite
establecer en qué proporción es mayor un valor de la variable que otro.
3. Organización y presentación de datos estadísticos
Una vez que disponemos de los datos los organizamos en una tabla donde en las columnas
definimos las variables y en las filas a los individuos. A esta tabla la denominamos base de datos

Una vez construida la base debemos realizar un análisis de consistencia de los datos y depurarla,
para lo cual podemos ayudarnos con la representación de las variables en tablas y gráficos. Este
resumen o representación depende del tipo de variable considerada, y permite realizar un primer
análisis de éstas. En las secciones siguientes trabajaremos con cada tipo de variable en particular, a
fin de poder organizar y presentar los datos. El resumen y la presentación de datos a través de tablas
y gráficos, permite mostrar la información de un conjunto de datos a una forma más simple, de tal
manera que facilita a quien los lee tener una idea general de su comportamiento, es decir de la forma
en que están distribuidos. Otro aspecto que consideraremos es si el análisis es para una variable, lo
que en estadística se denomina análisis unidimensional o si se analizan dos o más variables
conjuntamente, lo que se denomina análisis bidimensional o multidimensional. En esta asignatura,
veremos los dos primeros tipos (unidimensional y bidimensional), apuntando en este capítulo, a la
forma en que habitualmente se presentan los datos.
Distribuciones Unidimensionales
Comenzaremos con el análisis de las variables categóricas, para continuar luego con numéricas
discretas y continuas. En la sección anterior mostramos que en una base de datos cada fila
corresponde a una unidad de análisis y cada columna a una variable. Si tomamos una columna en
particular, la misma constituye lo que en estadística se llama una serie simple, la que muestra cada
una de las observaciones en el orden en que fueron recopiladas. A partir de esos datos elaboraremos
distribuciones de frecuencias.
Variables Categóricas
Para armar una tabla resumen de este tipo de variables, contamos la cantidad de casos que
pertenecen a cada clase o categoría, lo que se denomina frecuencia absoluta y calculamos la
proporción de casos en cada una de ellas, lo que se denomina frecuencia relativa, las que pueden
expresarse en porcentajes. Con estas frecuencias, se puede construir una tabla de tres columnas,
donde en la primera se anotarán las categorías y en las otras dos, la cantidad y el porcentaje de
observaciones
Cuando hablamos de frecuencia hacemos referencia a la repetición de cada valor o categoría de la
variable.
Clasificación de frecuencias:
● Frecuencia Absoluta: Es la cantidad de veces que se repite el valor. ( ni)
● Frecuencia Relativa: Es la proporción de veces que se repite la variable. Se calcula como la
frecuencia absoluta dividido el total de observaciones con el que estamos trabajando (hi = ni /
n)
● Frecuencia Absoluta Acumulada: Suma de las frecuencias absolutas ( Ni)
● Frecuencia Relativa Acumulada: Suma de las frecuencias relativas ( Hi)
- Las frecuencias acumuladas en el caso de este tipo de variables no son útiles, por lo tanto no es
necesario el cálculo de las mismas -
Esta información puede representarse gráficamente. Los gráficos no agregan información, pero se
emplean para tener una representación visual de la totalidad de la misma, presentando los datos de
tal modo que se pueda percibir fácilmente los hechos esenciales y compararlos con otros. En el caso
de variables categóricas, utilizamos el Diagrama Circular ( gráfico de torta o pastel) y el Gráfico de
Barras
En el Diagrama Circular se representa en el círculo el 100% de las empresas encuestadas y las
porciones o divisiones se hacen en función a los tipos de empresas según las frecuencias ya
indicadas. Puede utilizarse también el gráfico de barras, donde cada una de ellas representa una
categoría (en el ejemplo, un sector de la economía) y la altura de cada barra, la frecuencia
correspondiente.
El gráfico de barras debe cumplir con ciertas características:
● Para cada categoría debemos tener una barra
● La distancia entre las barras y el ancho de cada una debe ser igual (equidistante), representa
que todas las categorías tienen la misma importancia
● En el eje de las “y” se pueden representar tanto la frecuencia absoluta como la relativa
● Cada barra debe tener la altura correspondiente a la frecuencia de la categoría que
representa
Comentarios adicionales:
- Generalmente, es más frecuente que el gráfico de torta se utilice para representar frecuencias
relativas y el gráfico de barras para representar frecuencias absolutas -
- El porcentaje es más utilizado en estas variables (cualitativas), porque es mejor para la
interpretación -
Variables numéricas
En primer lugar, analizaremos las variables numéricas discretas, que son aquellas que provienen de
un proceso de conteo y que estarán representadas con números enteros.
Para resumir la información, construiremos la tabla de distribución de frecuencias de manera
análoga a como lo hicimos para las variables categóricas. En la primera columna de la tabla se
enumerarán los k valores distintos de la variable, que se denotan con xi para i= 1, 2,…,k, donde x1 es
el mínimo y xk es el máximo valor que asume. Observe que el número de distintos valores (k) que
asume la variable es siempre menor o a lo sumo igual al número de observaciones (n).
Las frecuencias simples (absolutas o relativas) se
representan en un gráfico de bastones donde para los
distintos valores que puede asumir la variable se levanta una
ordenada que representa la cantidad o porcentaje de
observaciones.
(Se diferencia con el de barras ya que este utiliza líneas)
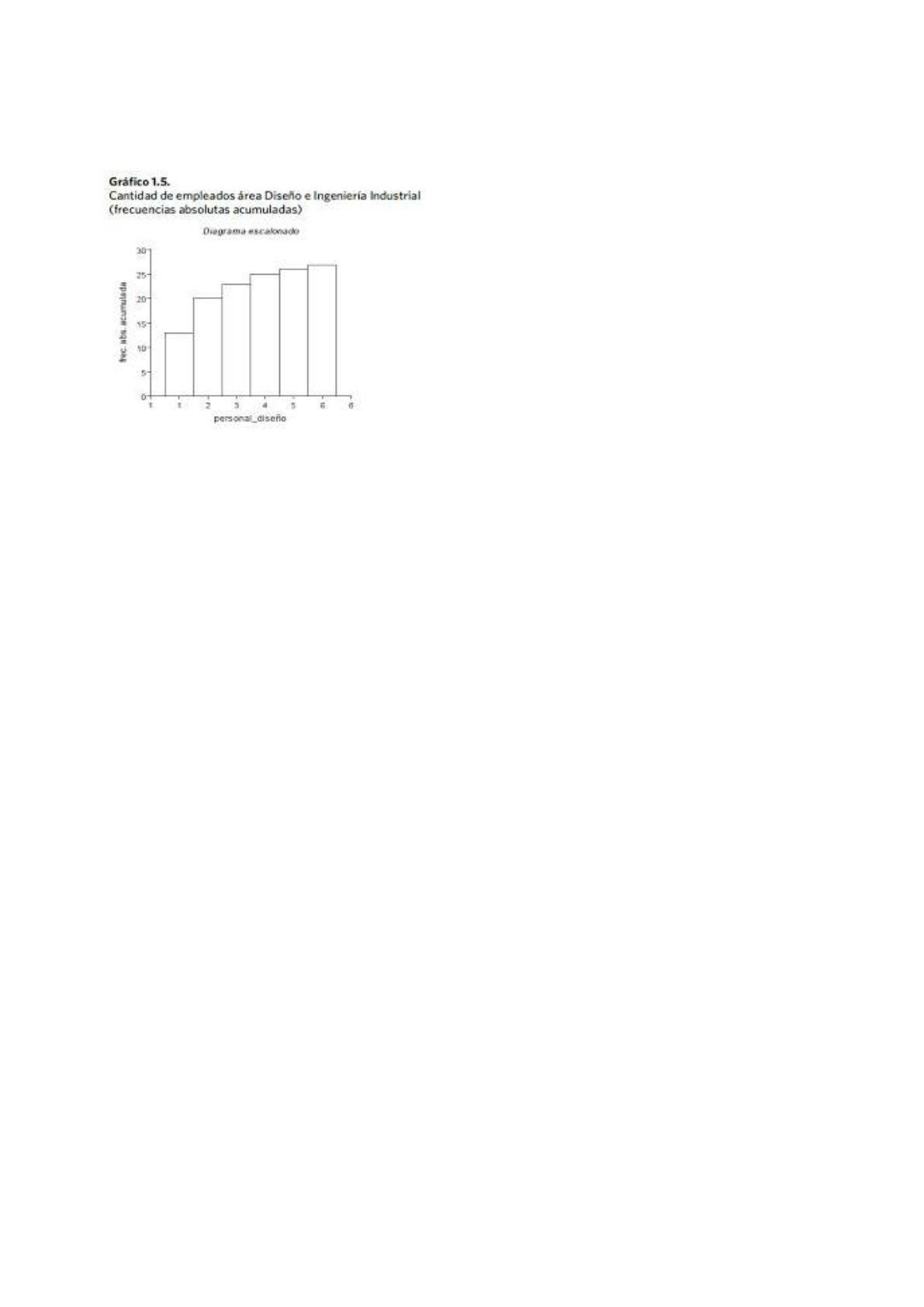
Para las frecuencias acumuladas (absolutas y
relativas) se utiliza un gráfico escalonado , donde
para cada valor xi se marca la frecuencia acumulada,
valor que se mantiene constante hasta el siguiente
donde se produce el próximo escalón.
Cuando trabajamos variables numéricas continuas es necesario agrupar los datos en intervalos.
(cabe aclarar que cuando la variable es discreta pero asume muchos valores distintos, puede
presentarse por una distribución de intervalos).
Previo a la confección de la tabla por intervalos, podemos realizar una exploración de este tipo de
datos utilizando el diagrama de tallo y hojas que constituye una variante de la distribución de
frecuencias. Este diagrama divide a las observaciones en digitos primarios y dígitos derivados.Por
ejemplo si las observaciones de los datos tuvieran por lo menos dos dígitos, la columna de las
decenas serían el dígito primario y la columna restante sería el dígito derivado. Si las observaciones
fueran de tres dígitos, el dígito primario está formado por las centenas y las decenas, y el dígito
derivado por las unidades. Cuando los datos están formados por más de tres dígitos es conveniente
cambiar la escala de medida.
Los dígitos primarios de los datos se denominan “tallo”, y los dígitos derivados “hojas”. La unidad de
hoja se refiere a la escala que se utiliza para presentar los datos en el diagrama.
A través de este gráfico podemos observar el comportamiento de la variable. Nos da una idea de la
concentración de los valores más frecuentes, los valores menores y los más grandes.
Para construir una tabla de distribución de frecuencias por intervalos, debemos seguir los siguientes
pasos:
1. Decidir la cantidad de intervalos de clase apropiados (k): Si bien depende de la cantidad
de observaciones con las que se cuenta, se recomienda establecer no menos de 5 intervalos
y no más de 20. Si fueran muy pocas clases los intervalos podrían ser muy grandes, es decir
cada intervalo abarcaría demasiada cantidad de observaciones como para permitir detectar
la tendencia de los datos. Por otra parte,tener demasiados intervalos se contradice con el
propósito que se persigue, que es resumir un conjunto grande de datos para facilitar el
análisis o la toma de decisiones.
2. Obtener la amplitud de los intervalos de clase ( c): Una opción que se utiliza
frecuentemente es que todos los intervalos sean de igual amplitud, lo cual facilita la
interpretación. Este valor c, se obtiene calculando la diferencia entre el valor más grande del
conjunto de datos (valor máximo) y el más pequeño (valor mínimo) dividiendo luego esta
diferencia entre el número de clases elegido. El desvío del numerador es lo que se conoce
como recorrido o rango ( R)

Por conveniencia y facilidad de lectura se deberá redondear siempre el valor de c por
exceso. Por último se repartirá la diferencia entre el nuevo recorrido y el original (R´- R) por
defecto y por exceso.
3. Establecer una regla general para definir los límites de intervalo de cada clase: Los
intervalos serán semiabiertos, por lo tanto, podrán ser abiertos por la izquierda o por la
derecha.
Para graficar las frecuencias absolutas o relativas simples de distribuciones por intervalos se utilizan
gráficos de superficie llamados Histogramas. El histograma está formado por rectángulos o barras
que se levantan desde el eje de las abscisas donde se ha marcado previamente los límites de cada
intervalo o clase en una escala numérica. La altura de cada una de las barras, que se registra en el
eje de ordenadas, se determina de manera tal que su área sea proporcional a la frecuencia de cada
clase, pudiendo representarse tanto las frecuencias absolutas como las relativas (o relativas en
porcentaje) cuando los intervalos son de igual amplitud.
Cuando los intervalos son de distinta amplitud, la altura de cada barra se obtendrá como la
proporción entre las frecuencias absolutas y la amplitud del intervalo (ni/ ci), fracción que se
denomina densidad de frecuencia. Será el resultado de esta fracción lo que marcará sobre el eje de
las ordenadas para cada intervalo.

Si suavizamos los extremos de cada intervalo, el histograma se transforma en un polígono de
frecuencias, que representa la forma tradicional de graficar un conjunto de datos de escalas
medibles.
El histograma y el polígono de frecuencias tienen la misma superficie, ya que cada porción de la
superficie (triangulo) del histograma, que se pierde en un extremo del intervalo de clase, se gana en
el otro extremo del mismo.
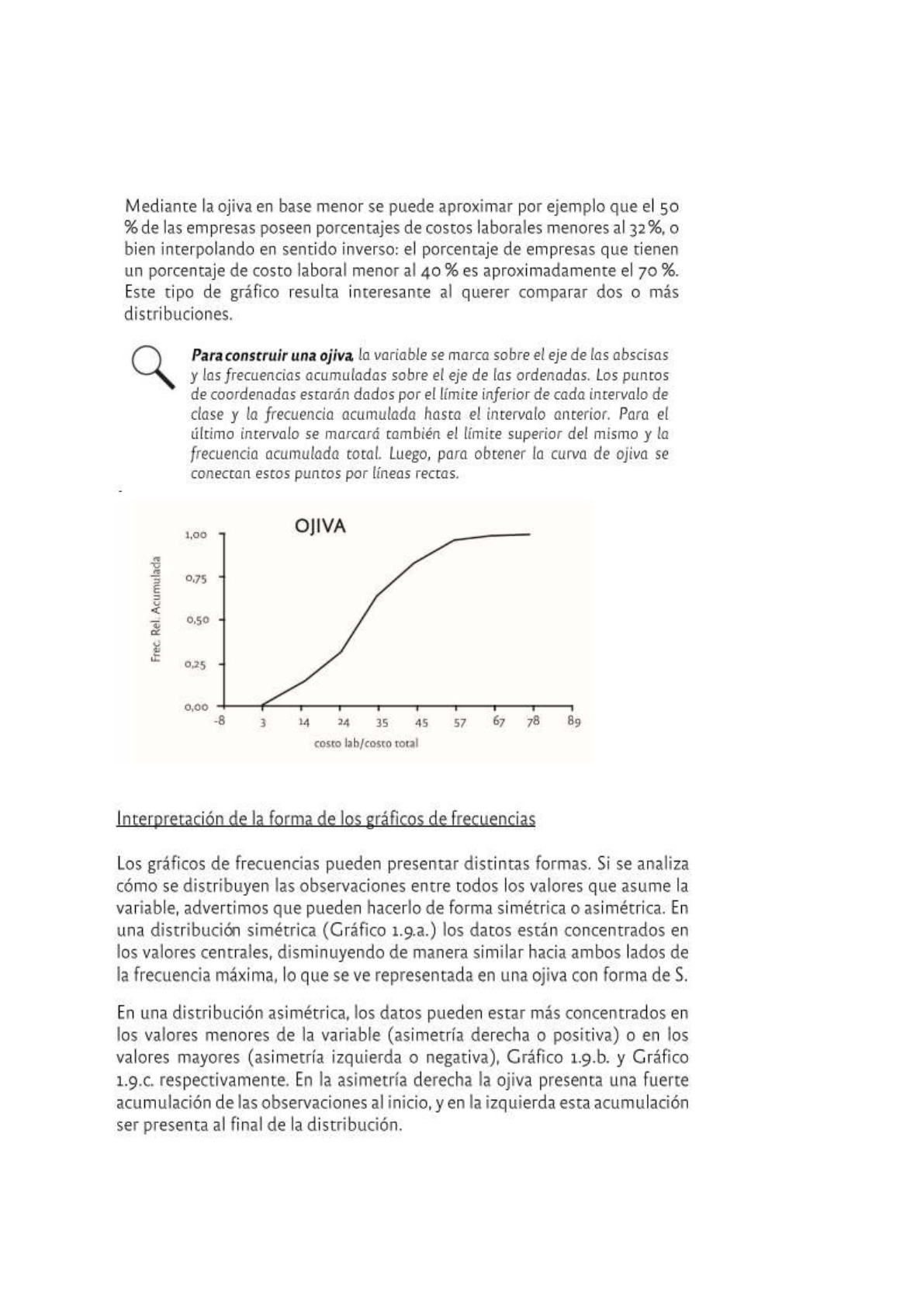
La representación grafica de las frecuencias acumuladas, cuando la variable es numerica continua,
es la ojiva, que es un grafico lineal y se utiliza cuando se desea aproximar cuantas o que porcentaje
de las observaciones estan por encima o por debajo de ciertos valores clave.
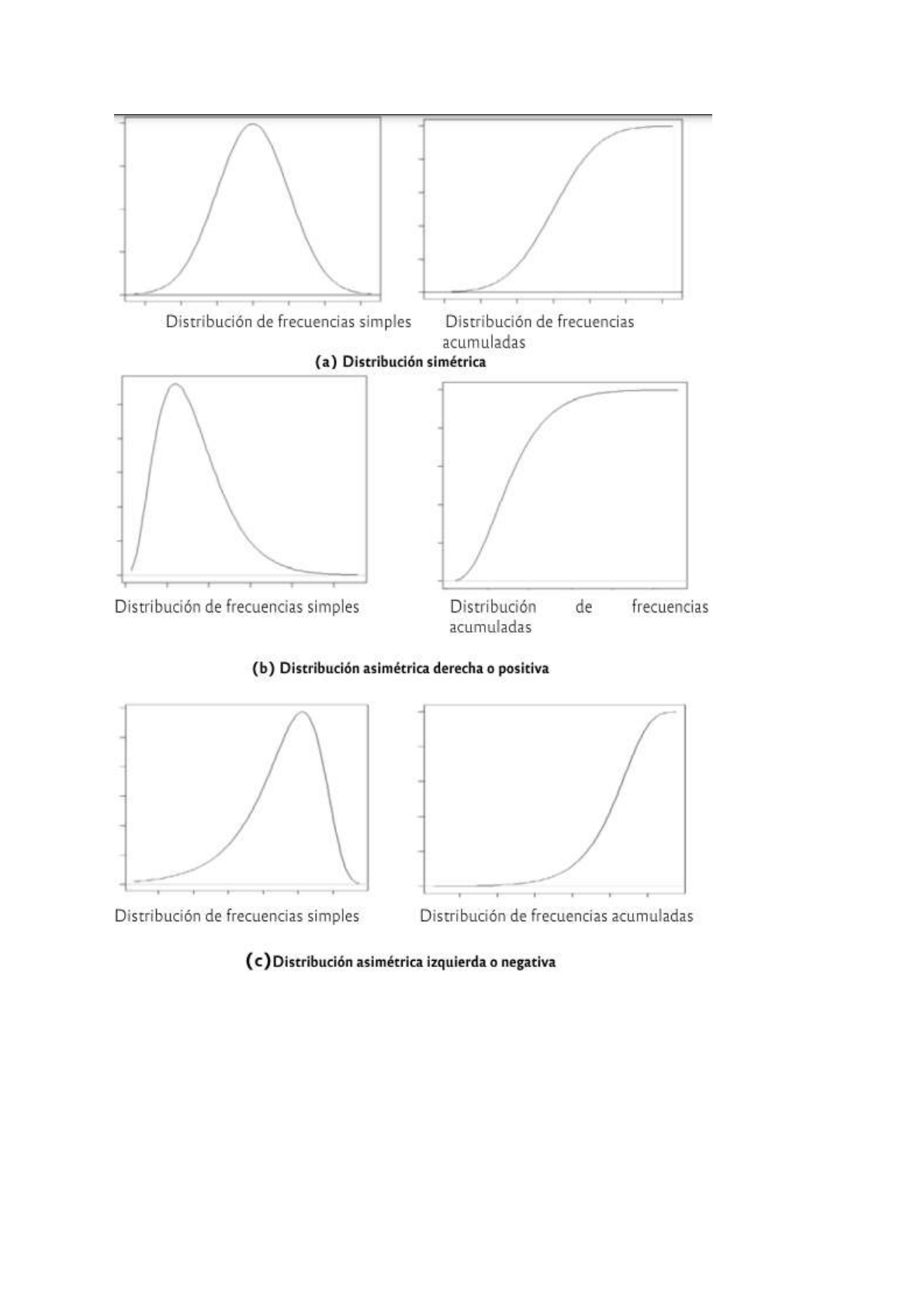

Distribuciones bidimensionales
Dos variables categóricas: Se construye una tabla de frecuencias conjunta denominada tabla de
contingencia. En esta tabla de contingencia una variable se representa en las filas y otras en
columnas, por lo tanto la tabla tendrá tantas filas y columnas como las categorías de las variables. En
cada celda de la tabla se representa la frecuencia (absoluta o relativa) asociada al par de categorías
que se intersecan entre la fila y la columna.
Los valores que presentan dos características conjuntamente se denominan frecuencias conjuntas.
Los totales por filas y por columnas se denominan frecuencias marginales.
Generalizando para las variables categóricas X con I categorías, e Y con J categorías, simbolizamos
con nij, a la frecuencia correspondiente a la categoría i de X conjuntamente con j de Y. Los totales
por fila se denotan “ ni. “ y los totales por columna “ n.j ”
En la tabla de contingencia se cumplen las siguientes relaciones:

Si dividimos todos los valores de la tabla por el total de observaciones, se obtienen las frecuencias
relativas conjuntas , que denotaremos como “ hij “, y se calculan como:
Las frecuencias relativas pueden ser más útiles que las absolutas en algunas interpretaciones.
Para graficar frecuencias absolutas o relativas conjuntas se pueden utilizar los gráficos de barras
múltiples o los de barras componentes o apiladas.
En un gráfico de barras múltiples se representa, para cada categoría de una variable, tantas barras
como categorías de la otra, y la altura de cada barra es el porcentaje de frecuencia conjunta entre las
dos categorías analizadas.
Este tipo de gráfico es muy útil cuando una de las categorías es dicotómica.
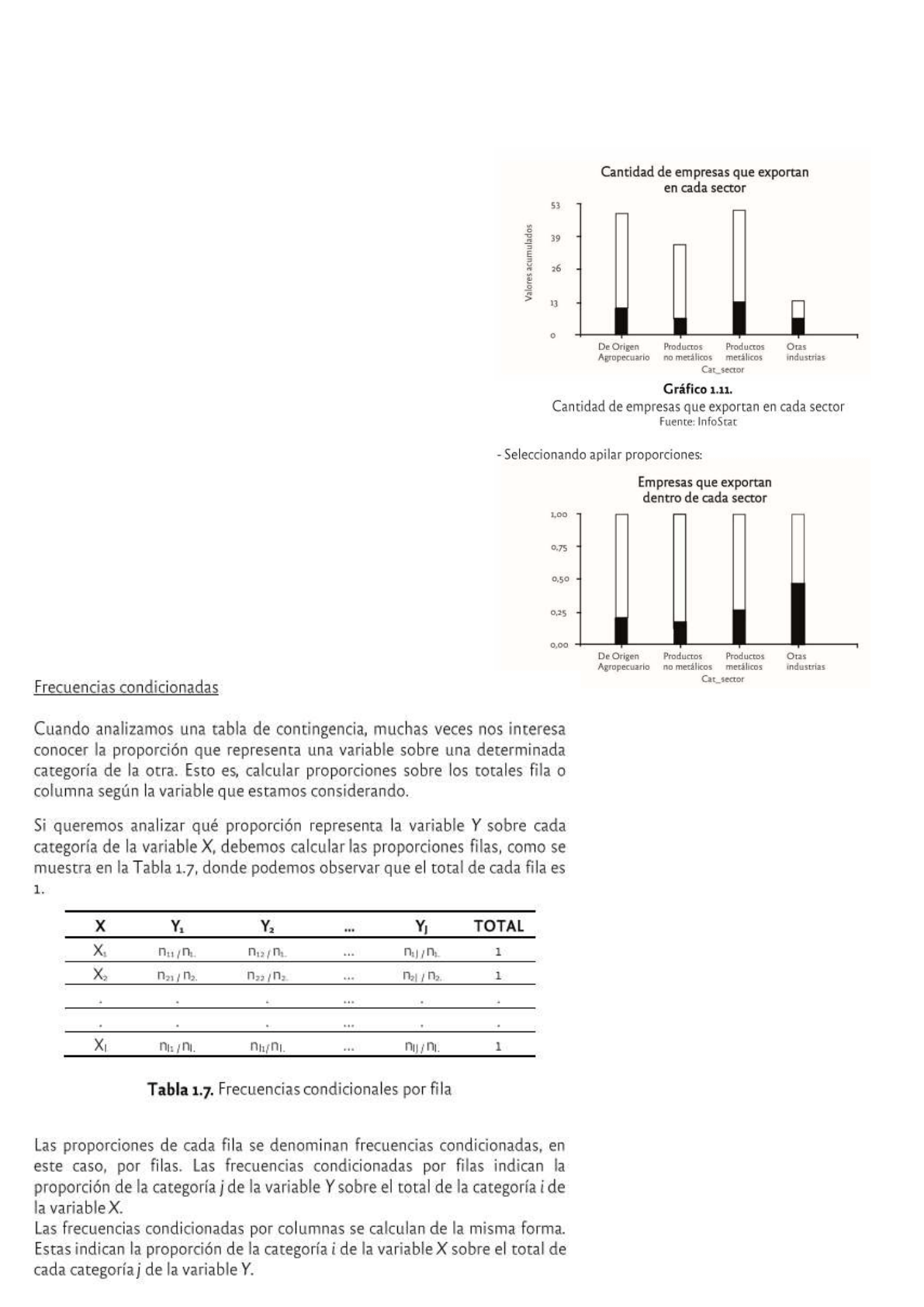
En cambio, en un gráfico de barras componentes, cada barra representa cada categoría de una
variable y se divide en tantas partes como categorías de la otra
.
Este documento contiene más páginas...
Descargar Completo
Estadistica- Unidad 1.pdf
 Estamos procesando este archivo...
Estamos procesando este archivo...
 Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Descargar
Estamos procesando este archivo...
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.