
ESTADISTICA
Primer parcial:
Unidad I: Razones y Porcientos: Se entiende por razón o proporción al cociente entre
dos números, en donde el numerador es la cifra que se desea comparar y el
denominador, el número respecto al cual se compara y que generalmente se denomina
base de comparación. Entre los usos de las razones y porcentajes pueden mencionarse:
- Permiten trabajar con cifras pequeñas, fáciles de entender, generalmente menores a
100.
- Reducir un conjunto de cifras a una base común.
- Relacionar dos magnitudes.
- Determinar aumentos o disminuciones relativas entre dos cifras, en general, identificar
variaciones entre cifras.
En el caso de que se quiera comparar a un número A con un número B (base de
comparación), al cociente A/B se lo conoce como nivel y puede interpretarse como
cuántas veces es A con respecto a B. Si A y B están expresados en la misma unidad de
medida (ej, $), A/B no tendrá unidad de medida. Si a este número se lo multiplica por
100 se lo conoce como porcentaje (A/B*100), y se lo mide en %.
Por otro lado, a la diferencia A - B se la conoce como variación absoluta, y se expresa en
la misma unidad de medida que A y B; es decir, si A y B se expresa en Km., A-B también.
También es de interés comparar la variación absoluta con respecto a la base, lo que se
conoce como variación relativa (o simplemente como variación), y se expresa como
(A-B)/B que es lo mismo que (A/B – 1). Si este número es positivo (negativo), se
interpreta como cuantas veces más o mayor (menos o menor) es A con respecto a B. Si
a estas expresiones se las multiplica por 100: [(A-B)/B]*100, el resultado se lo conoce
como variación porcentual.
NIVEL: A/B PORCENTAJE: (A/B)*100 VARIACIÓN ABSOLUTA (VA): A – B
VARIACIÓN RELATIVA: VA/B VARIACIÓN PORCENTUAL: (VA/B)*100
Unidad II:
Estadística: Pasos de un estudio estadístico:
1) Especificación: Definición de población estadística: Es el conjunto de personas,
objetos, entes etc, definidos en una dimensión espacio y en una dimensión
tiempo; Definición de elemento unitario: Persona, objeto o ente del cual se
desea obtener información; Definición de Variable: Una variable (X) es una
característica que puede observarse, contarse o medirse en cada uno de los
elementos unitarios y que varía al pasar de un elemento a otro. Definición de
Dato u observación: Valor que toma la variable para cada elemento unitario.
2) Métodos de recopilación.
3) Presentación.
4) Análisis e interpretación.
Tipos de variables: Las variables pueden expresarse numéricamente (cuantitativas),
por ejemplo, edad, altura, número de hijos, etc, o cualitativamente (en categorías),
por ejemplo sexo, nivel de educación, estado civil, color de ojos etc.
Podemos clasificar a las variables cualitativas en:
a) Dicotómicas/ clasificación múltiple: La primera sólo admite dos categorías,
por ejemplo, posee auto. La segunda, admite más de dos categorías.
b) Nominal/ ordinal: En la primera no hace falta ordenarla, por ejemplo, sexo,
estado civil. En la segunda, es necesario qué esté ordenado de menor a mayor, por
ejemplo, nivel de educación.
c) Natural/ arbitraria: En la primera, las categorías no las pone el investigador, por
ejemplo, sexo, nivel de educación, estado civil. En la segunda, las categorías las
pone el investigador, por ejemplo, estado de salud, clasificaciones de los ingresos.
Podemos clasificar las variables cuantitativas en:
a) Cuantitativas discretas o discontinuas: Sus valores surgen del hecho de
contar o enumerar, entre dos valores consecutivos no existen valores intermedios.
b) Cuantitativas continuas: Sus valores surgen del hecho de medir, entre dos
valores consecutivos existen infinitos valores intermedios. Este tipo de variable es
continua independientemente del instrumento de medición
Distribución de frecuencias: Es una técnica para presentar y resumir datos
estadísticos. Ventajas y Desventajas: Aumentan la capacidad de percepción
de las cosas. Sirven para analizar la variabilidad de los datos estadísticos
(información). Permiten ganar en comprensión, pero se pierde detalle.
Variabilidad: No coincidencia de los valores observados de la variable.
Distribución de frecuencias en variables cuantitativas continuas: Pasos para su
realización:
1) Recolectar los datos.
2) Ordenar los datos.
3) Determinar el rango. R=Xmax – Xmin.
4) Determinar la cantidad de clases (C.C): Regla de Sturges: C.C= 1+3,33 log N
C.C= √N; C.C= R/h h (amplitud del intervalo)
5) Límites de clases (superior e inferior).
6) Requisitos de los intervalos: Excluyentes, exhaustivos y adyacentes.
7) Puntos medios (xi): xi= (límite superior + límite inferior)/2.
Dato apareado: Par de valores, uno de la variable X y otro de la variable Y, que se
simbolizan (xi ; yj) y que se obtienen de cada elemento unitario de la
población por la medición simultánea de ambas variables.
Distribución de frecuencia a dos variables: Tabla estadística que
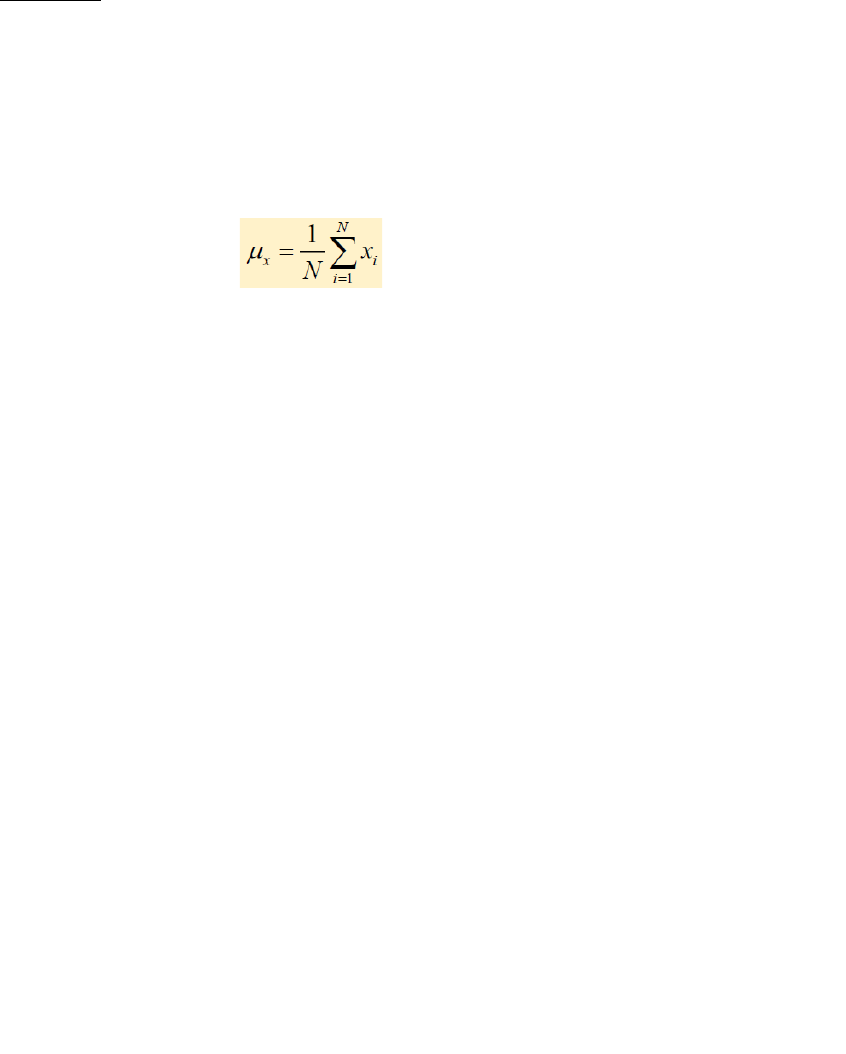
presenta las “frecuencias conjuntas” de las distintas “clases apareadas” de dos
variables, siendo por lo tanto un resumen de una serie de datos apareados obtenidos
de una población estadística. Tiene como objetivo mostrar y analizar como se
combinan los distintos valores de dos variables.
Unidad III:
Promedios: Son los valores de las variables que resumen o caracterizan a un conjunto
de datos estadísticos. Se expresan en las unidades de medida de la Variable.
EN DATOS SIN AGRUPAR:
Media Aritmética (µx): Es el cociente entre la suma de los valores de la variable y
el número total de ellos.
Características: Igual unidad de medida que la variable. Valor calculado, puede o no
coincidir con los de la variable. Influencia de valores extremos. Fácil cálculo y
rigurosidad de definición. Permite operaciones algebraicas.
Mediana (Me): Es aquel valor de la variable que excede al 50 % de las
observaciones y es excedido por el 50% restante de ellas, cuando los
valores están ordenados. Ubicación en datos sin agrupar: (N+1)/2
Características: Igual unidad de medida que la variable. Para datos impares, coincide
con un valor de la variable. Para datos pares, es un valor calculado. No se encuentra
influenciado por valores extremos. Fácil cálculo y rigurosidad de definición. No es de
fácil tratamiento algebraico
Cuartiles (Q1 y Q3): Q1: Es el valor de la variable que excede el 25% de las observaciones
y es excedido por el 75% restante, cuando los valores están
ordenados. Ubicación en datos sin agrupar: (N+1)/4
Q3: Es el valor de la variable que excede el 75% de las observaciones y es excedido
por el 25% restante, cuando los valores están ordenados. Ubicación en datos sin
agrupar 3(N+1)/4.
Modo (Mo): Es aquel valor de la variable que se repite mayor cantidad de veces o se
presenta con mayor frecuencia entre el conjunto de valores de la característica que se
investiga.
Características: Igual unidad de medida que la variable. Valor observado, coincide con
un valor de la variable. No se encuentra influenciado por valores extremos.
EN DATOS AGRUPADOS:
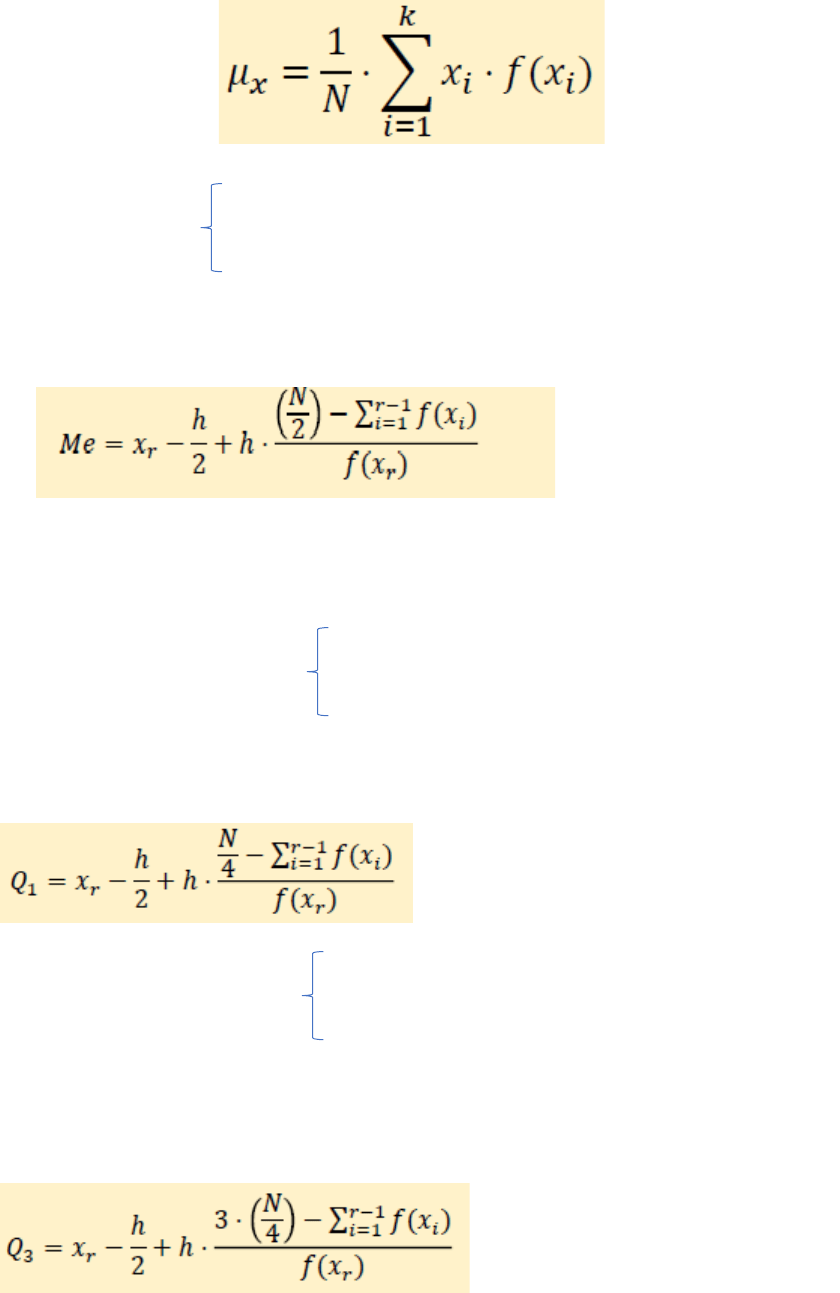
Media Aritmética(µx):
F(x) ≥ 0,50 N
Mediana: Ubicación
F´(x) ≥ 0,50 N
Una vez ubicada la “Clase Mediana”, si la misma contiene más de un valor de la
variable, debe aplicarse la fórmula de interpolación para encontrar el valor del
Promedio buscado.
xr= Punto medio = xi F(xr)=F(xi) h=Amplitud del intervalo
F(x) ≥ 0,25N
Cuartil Primero (Q1): Ubicación
F´(x) ≥ 0,75N
Una vez ubicada la “Clase del Q1”, si la misma contiene más de un valor de la variable, debe
aplicarse la fórmula de interpolación para encontrar el valor del Promedio buscado.
F(x) ≥ 0,75N
Cuartil Tercero (Q3): Ubicación
F´(x) ≥ 0,25N
Una vez ubicada la “Clase del Q3”, si la misma contiene más de un valor de la variable,
debe aplicarse la fórmula de interpolación para encontrar el valor del Promedio
buscado.
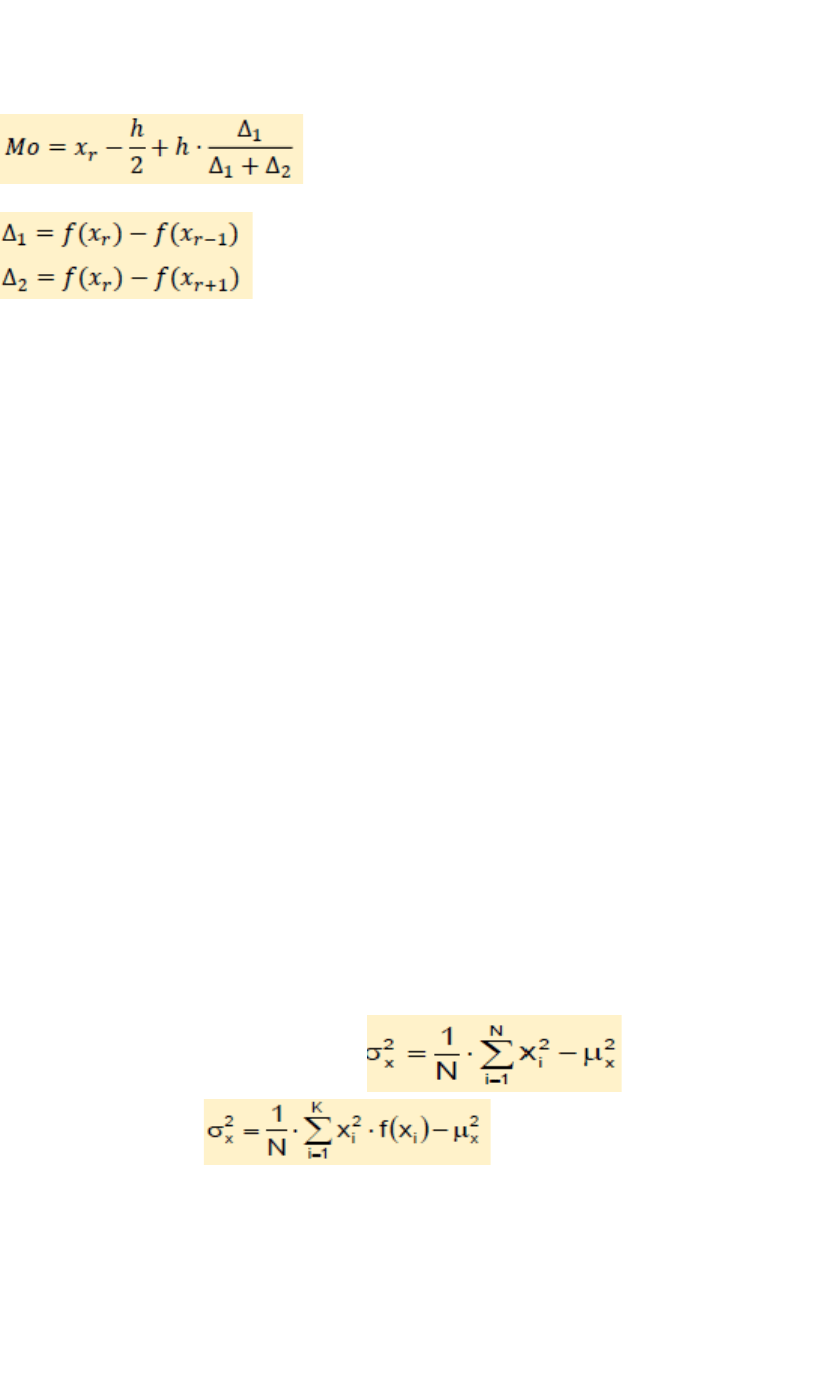
Modo (Mo): Buscamos la Mayor frecuencia [f(xi) mas grande]. Una vez ubicada la
“Clase Modal”, si la misma contiene más de un valor de la variable, debe aplicarse la
fórmula de interpolación para encontrar el valor del Promedio buscado.
Donde:
Relación Empírica de magnitud entre los promedios (relación de Pearson entre los
promedios):
a) Distribuciones simétricas: µx=Me=Mo
b) Distribuciones asimétricas o sesgadas a la derecha: µx>Me>Mo
c) Distribuciones asimétricas o sesgadas a la izquierda: µx<Me<Mo
d) Distribuciones unimodales y moderadamente asimétricas: µx-Mo≡3*( µx-Me)
Medidas de Variabilidad o Dispersión: Permiten conocer la representatividad de los
promedios de los valores observados de la variable. Pueden ser absolutas o relativas:
Absolutas: Rango (R); Rango Intercuartil (RI); Varianza (σ²x); Desviación Estándar (σx).
Relativas: Coeficiente de Variabilidad Relativa (CVR)
Rango (R)= Xmax – Xmin
Características: Cálculo y significación sencillos. Medida muy inestable. No da idea del
carácter de la distribución dentro de las observaciones extremas.
Rango Intercuartil (RI)= Q3 – Q1
Características: Describe variabilidad para el 50% de los valores centrales de los datos.
Cálculo y significación sencillos. No da idea del carácter de la distribución dentro de los
cuartiles. No se adapta a cálculos algebraicos
Varianza (σ²x) = En datos sin agrupar:
En datos agrupados:
Características: Valores en unidades cuadráticas. Difícil interpretación.
Desviación Estándar (σx)= √σ²x
Características: Se mide en las unidades de la variable. Está afectada por cada valor de
la variable. Se adapta a cálculos algebraicos.
Coeficiente de Variabilidad Relativa (CVR)= (µx/σx)*100
Características: Se usa para comparar variabilidades cuando: Las unidades de medidas
de las variables son diferentes. Las unidades de medidas de las variables son iguales,
pero las Medias Aritméticas son diferentes.
Medidas de Asimetría:
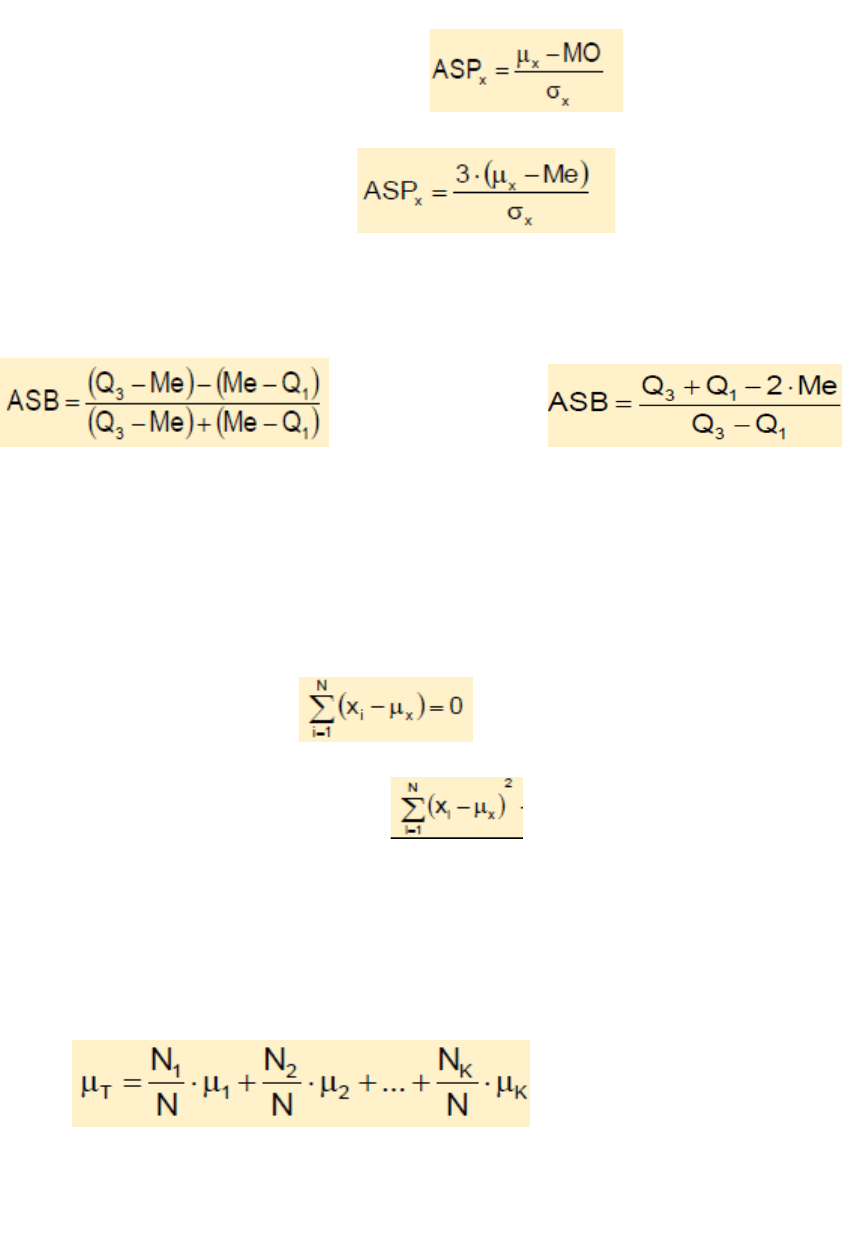
Coeficiente de Asimetría de Pearson (ASPx):
Límites de variación: -3≤ ASPx ≤ 3
Como µx-Mo≡3*( µx-Me), entonces:
Coeficiente de Asimetría de Bowley (ASBx): Mide la forma de la distribución de
frecuencias en el 50% central de los valores de la variable.
Límites de variación: -1≤ASBx≤1
o lo que es lo mismo:
Distribución simétrica: σx ≈ R/6
Distribución moderadamente asimétrica: σx ≈ R/4
Propiedades de la Media Aritmética:
1) La suma de los desvíos lineales de cada valor de la variable respecto a la Media
Aritmética es igual a 0.
2) La suma de los desvíos cuadráticos de cada valor de la variable respecto a la
Media Aritmética es un mínimo. mínimo.
3) Si a cada valor de la variable, se le suma una constante, la Media Aritmética
queda sumada en la constante. µx+k = K + µx.
4) Si a cada valor de la variable, se lo multiplica por una constante, la Media
Aritmética queda multiplicada por la constante. µx*k = K*µx.
5) Cuando se tienen dos o más poblaciones mutuamente excluyentes y, en ambas
se estudia la misma variable, la Media Aritmética de todas ellas es igual a:
Propiedades de la Varianza:
1) Si a cada valor de la variable, se le suma una constante, la Varianza no se altera.
σ²x+k = σ²x

2) Si a cada valor de la variable, se lo multiplica por una constante, la Varianza
queda multiplicada por la constante al cuadrado. σ²x*k= k²* σ²x
3) Cuando se tienen dos poblaciones mutuamente excluyentes y, en ambas se
estudia la misma variable, la Varianza de todas ellas es igual a:
Unidad IV: Muestreo
Censo: Relevamiento de la información de interés sobre todo el conjunto de
elementos que conforman la población a investigar.
Muestreo: Relevamiento de la información sobre una parte de los elementos que
conforman la población investigada. La selección de los elementos que integran la
muestra puede hacerse por un experto (Muestreo no Probabilístico) o por un proceso
aleatorio (Muestreo Probabilístico). Los estadísticos o estimadores, que son las
características de la muestra ( ,s²) estiman a los parámetros poblacionales, que son
las características de la población (µx, σ²x)
Objetivos de las técnicas muestrales: Usando la información obtenida de una parte del
conjunto (muestra), estimar información sobre todo el conjunto (población); y estimar
la calidad de esta en el sentido de en cuánto discrepa de la verdadera información.
(Controlar el error).
Tipos de errores que se cometen en un muestreo: ERRORES MUESTRALES: Diferencia
entre el valor de un estimador (información muestral) y su correspondiente parámetro
poblacional (resultante de un relevamiento total de la población). ERRORES NO
MUESTRALES: Comprenden todos los errores que se pueden presentar en el transcurso
de la investigación, salvo el error muestral. (Sesgo de selección y Sesgo de medición)
Tipos de muestreo: Muestreo probabilístico: Todos los elementos de la población
tienen una probabilidad de ser seleccionados para la muestra; La selección de las
unidades muestrales es al azar (sorteo o tablas de números aleatorios); Es posible
calcular el valor hasta el cual el valor del estimador puede diferir del valor de
parámetro de la población de interés (error muestral) con cierta probabilidad. Es el
proceso por el cual cada unidad muestral seleccionada para la muestra se realiza en
base a un sistema aleatorio (sorteo o tablas de números aleatorios). Este sistema de
selección cuenta con técnicas estadísticas que permiten estimar y controlar la
magnitud del error muestral.
Muestreo no probabilístico: La inclusión de los elementos en la muestra se basa en el
criterio de la persona que realiza el muestreo; Carece de técnicas estadísticas que
permitan estimar y controlar la magnitud del error muestral. Es el proceso por el cual
cada unidad muestral seleccionada para la muestra es escogida por una persona con
experiencia y conocimiento sobre el problema que se desea investigar. Este sistema de
muestreo carece de técnicas estadísticas que permitan estimar y controlar la magnitud
de error muestral. Es subjetivo, al determinarse la muestra a veces por conveniencia,
no asegura representación total de la población por lo que no se puede generalizar ni
hacer inferencia probabilística.
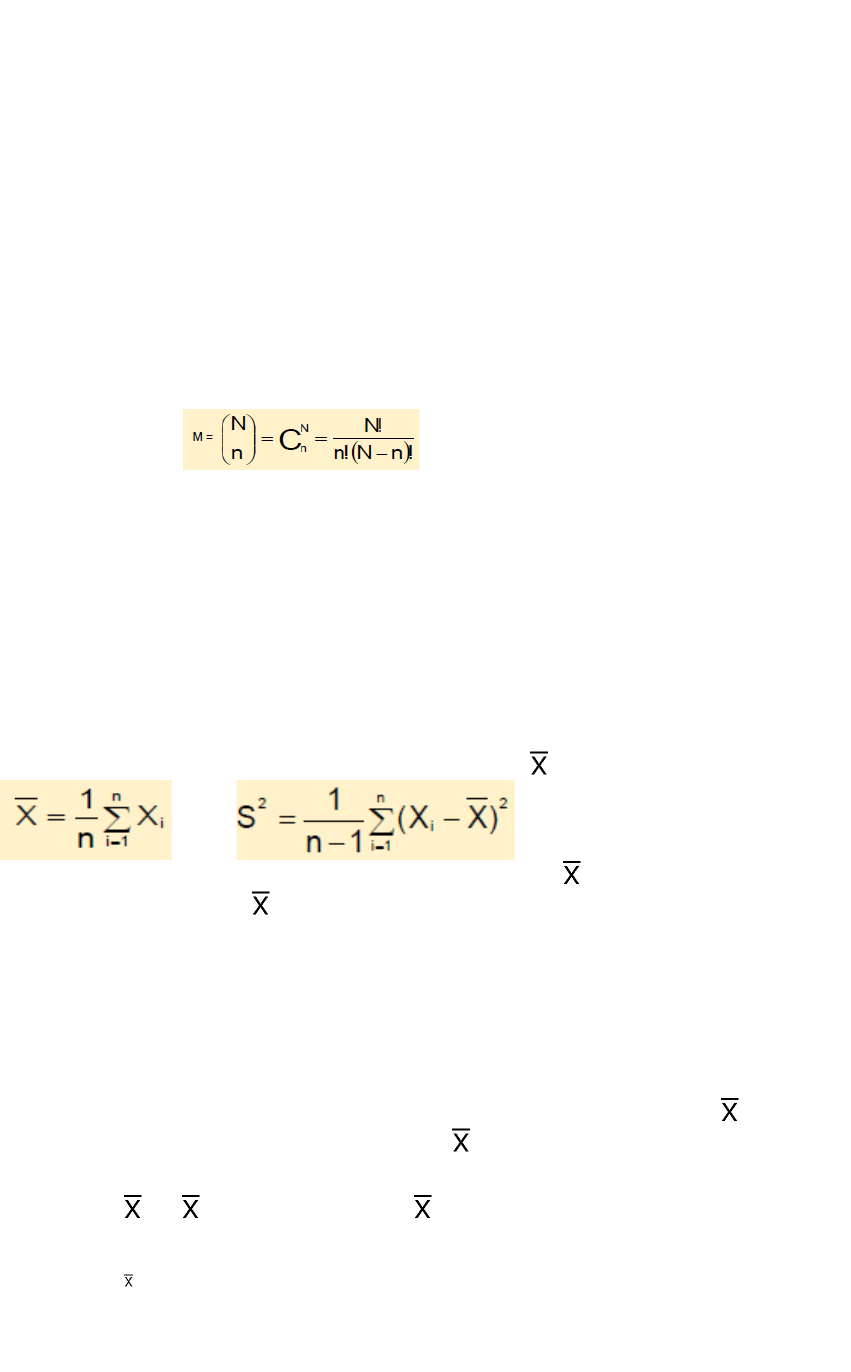
Teoría del muestreo: Marco de referencia construido con la finalidad de cuantificar el
error muestral para su eventual control. Para construir esta teoría es necesario
considerar todas las muestras al azar posibles de un tamaño previamente especificado,
que se puedan extraer de una población. La teoría muestral se construye en base a
dos conceptos fundamentales: Que la información muestral trate de informar sobre la
población (carencia de sesgo) y que el error muestral sea mínimo (máxima eficiencia).
Muestra simple al azar con reposición y con repetición (esquema con y con): son
aquellas que tienen igual probabilidad de ser escogidas y en las que cada componente
tiene igual probabilidad de estar presente en la muestra.
Muestra simple al azar sin reposición y sin repetición (esquema sin y sin): son aquellas
que tienen igual probabilidad de ser escogidas y en las que cada componente tiene una
probabilidad conocida de estar presente en la muestra.
Numero de muestras (M) dependiendo del tipo de esquema:
Esquema con y con: M=N˄n
Esquema sin y sin:
Deducción estadística: Es un proceso teórico. Analiza cómo la Población transmite sus
características a las muestras.
Inducción estadística: Es un proceso práctico. Analiza cómo hacer estimaciones de los
Parámetros a partir de la información de la muestra.
Proceso de deducción estadística: Esquema con reposición y con repetición:
Paso 1: Generar todas las muestras posibles, con un tamaño previamente especificado.
Construir un marco muestral con cada sujeto enumerado del 1 al N. Usando una
fuente de números aleatorios, seleccionar números entre 1 y N, n veces.
Varianza estrella (*σ²x)= σ²x *(N/N-1)
Paso 2: Calcular en cada muestra generada, su media ( ) y su variabilidad (s²)
Paso 3: Construcción de las distribuciones muestrales de ( ) y de s².
Distribución muestral de ( ): Es la distribución que resume todas las medias
muestrales calculadas a partir de los datos resultantes en cada una de las muestras
posibles, seleccionadas para un dado tamaño n. Cualquier distribución muestral
siempre se refiere a: Una población específica que está siendo muestreada y a un
tamaño específico de muestra aleatoria simple.
Paso 4: Calcular media y varianza de los estimadores a partir de sus distribuciones
muestrales.
Paso 5: Verificar teoremas sobre el valor esperado de los estimadores y V( ): La media
aritmética de las distribuciones muestrales de , es igual a la media aritmética de la
población de donde proceden las muestras.
Teorema: µ( )=E( )=µ(x). Un estimador se dice que es insesgado si su distribución
muestral tiene una media igual al parámetro que estima.
Teorema: σ² = σ²x/n. Las distribuciones muestrales se concentrarán más alrededor del
parámetro (µ) sobre el que se desea obtener la información, a medida que menor sea
la variabilidad (σx) de la población de donde provienen las muestras. Las estimaciones

tenderán a concentrarse más alrededor del parámetro, a medida que mayor sea el
tamaño de la muestra.
Resumen de características de la distribución de la Media muestral:
• Contiene los resultados de todas las muestras aleatorias posibles.
• El valor esperado de la Media Muestral es igual a la media poblacional.
• Presenta menos variación que la distribución de la población.
• Su variabilidad es afectada por el tamaño de muestra y por la variabilidad de la
población en estudio.
• Permite conocer las magnitudes posibles del error muestral y las frecuencias con que
pueden presentarse.
• Permite conocer la precisión con la cual se puede estimar la media de la población en
base a cualquier muestra aleatoria simple.
Teorema: µ(s²)=E(s²)= σ²x. s² es un estimador insesgado de la varianza (σ²x) en el
esquema con y con.

ESTADISTICA.pdf
 Estamos procesando este archivo...
Estamos procesando este archivo...
 Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.
Descargar
Estamos procesando este archivo...
Lamentablemente la previsualización de este archivo no está disponible. De todas maneras puedes descargarlo y ver si te es útil.